分享专家:聂凡博,唯品会基础架构离线大数据组件研发Lead
唯品会离线数据平台架构
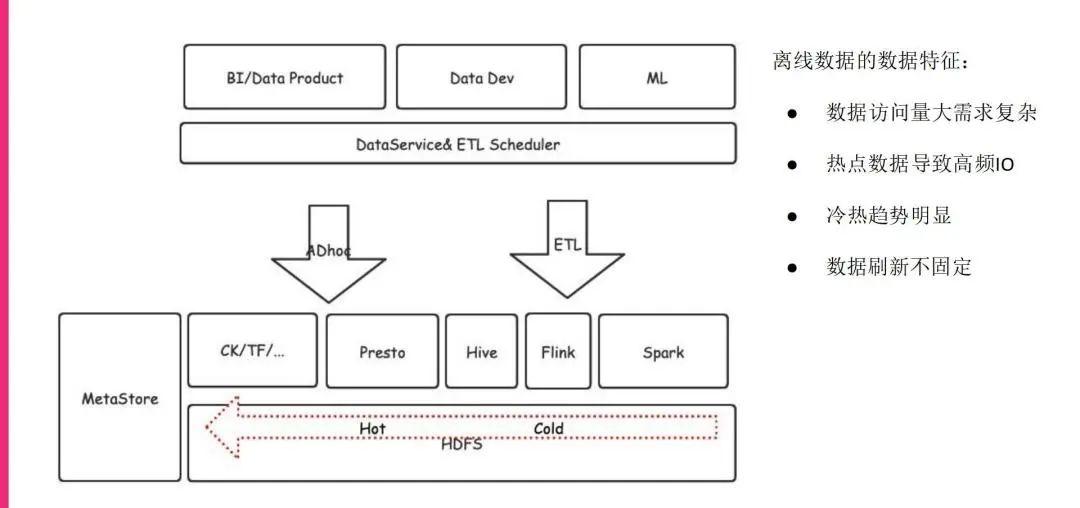
这是目前我们筹划的一个离线数据平台的大致架构,可以看到我们上面对接的数据访问是非常大的,有各种各样的产品应用,有BI的产品,有数据开发,还有一些机器学习的东西,它们都会对接我们的调度系统。
调度系统大致会分成AD hoc的查询或者是ETL的作业,它们最终会到计算引擎这一层,最终会访问HDFS。
我们现在的HDFS是做了切分的,做了很多存算分离,但即便如此,对于很多访问量非常大、非常高频的数据,也会出现明显的数据倾斜以及冷热不均衡的问题。并且因为我们的作业非常多,量非常大,这些作业的设计模式是它们从属的开发人员自己设定的,所以这些数据的刷新频率也是不固定的,可能每天刷一次,也有可能每5分钟刷一次,甚至也有可能发现数据有问题的时候随时对数据进行刷新,这些都对后续使用类似Alluxio这样的缓存技术带来一定的障碍。
热数据场景分析
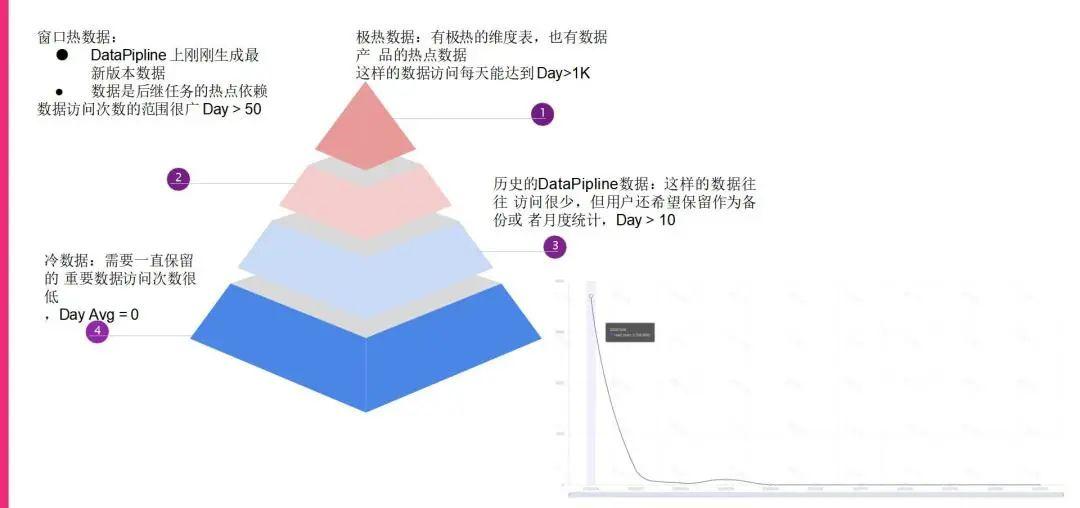
下面就对于我们现在的热数据场景做了很多分析:
-
我们发现,金字塔最顶端就是那些极热的数据,往往是我们经常要查询或者说要look up查询的一些维度表,它们的数据量甚至能够达到一天要访问1000次以上,这里的次数是已经做完清洗,去除掉文件数量干扰的,所以就是那一份数据的准确访问次数。
-
对于温热层,我们可以看到基本上都是在ETL这一层产生的Data Pipeline的数据,就是产生了一份中间数据,或者产生了一些DW层的数据,给后期的很多任务去使用,可能后期任务有很多,所以说这个数据也是温热的,可能有几百个或者上千个后继任务都在使用这个数据,所以它的访问次数也是不低的。
-
最底层的话就是冷数据,往往我们生成完了这些历史的Data Pipeline的数据,它在过了一段时间之后,就没有人再去访问了,但是可能对于一些特殊的事件,比如说大促的时候,会进行一些对照的分析,所以这些数据会要求长期保留的,但是平均的访问时间其实很低几乎没有,所以我们认为这些是冷数据。
我旁边也贴了一个图,这个图就是一个比较典型的数据场景,这份数据在它刚刚生成的时候是非常热的,它的访问次数非常高,但是随着时间的流逝,就迅速地冷化下来了,后面几乎没有人访问,这就是我们典型的一个数据访问场景。
数据步长
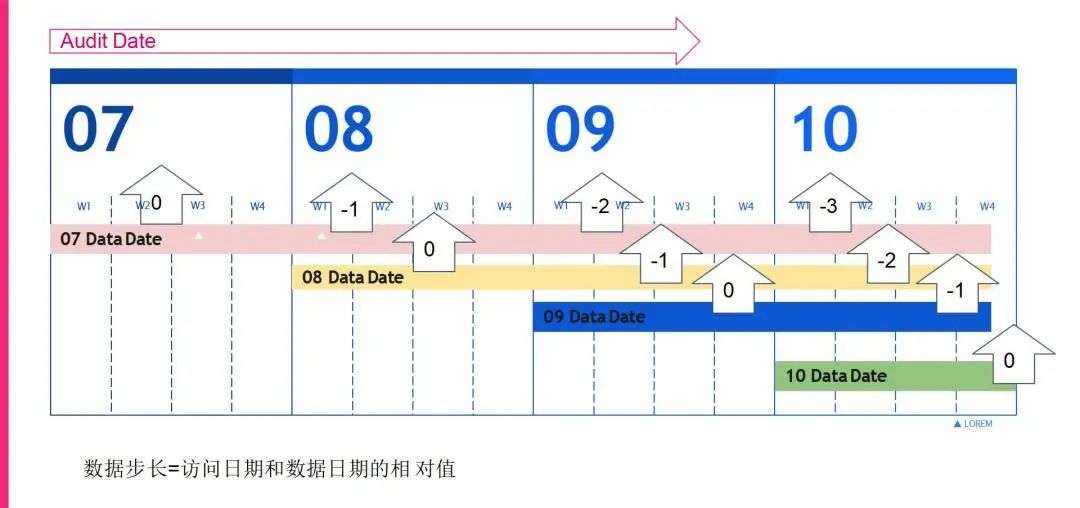
基于我们现在的数据访问场景,我们自己定义了一个方案去更好地去统计分析这些数据访问。我们定义了数据步长这样一个概念。
就是说随着日志访问的日期往前推移,我们的数据产生的时间和日志日期之间的相对差值就是步长。比如说我在7号生成的数据,相对于7号这个日志日期来讲是0的步长,到了8号之后,我7号产生的数据就变成了-1的步长,到了9号就是-2,以此类推,那我8号的数据在8号来讲也是0的步长。
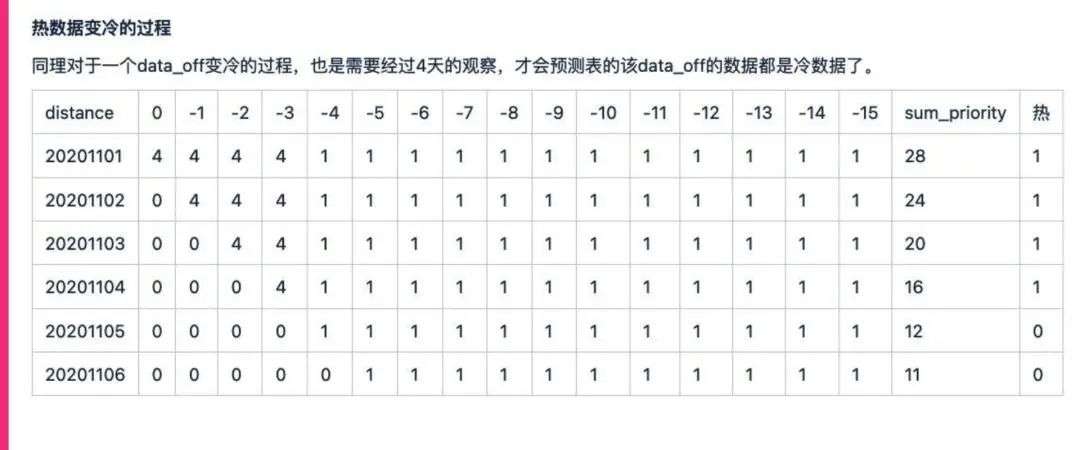
所以通过这个相对步长,我们就能够比较清晰地看到,针对于日志日期往前推,相对步长的数据访问其实是比较固定或者相对固定的,也就是说一张表的数据,今天日志生成的今天数据日期的数据,实际上访问量基本上是固定的,今天生成数据到明天就是-1的步长,这样的数据访问的量级也是相对固定的,可能会降一个量级。
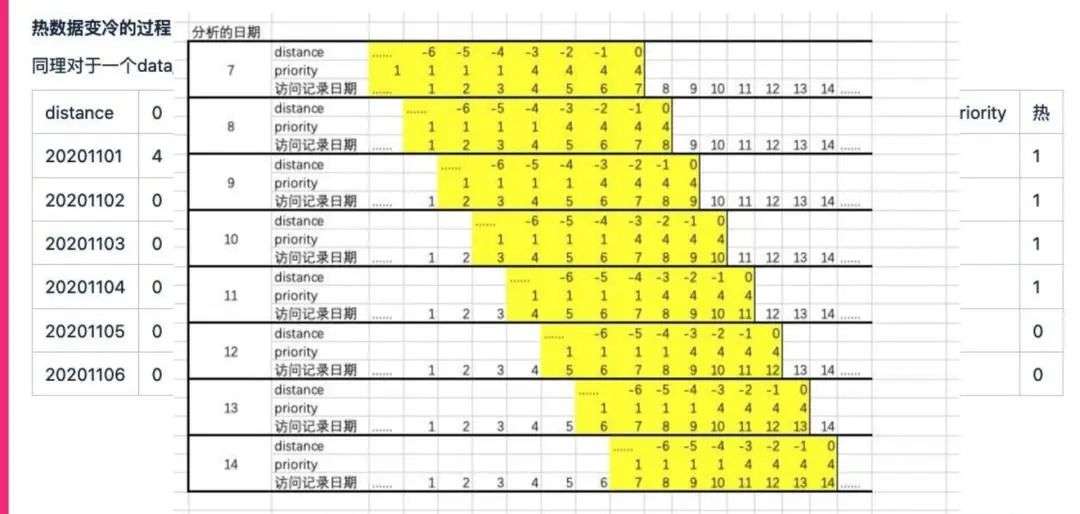
所以我们就能够总结出一定的规律,也就是说基于相对步长,我们能够大致拿到每一张表对于这个相对步长的分区访问的频率大概是什么样子的。
基于数据步长的数据冷热数据

所以,根据相对步长的分析,我们能够进而总结每个表级的相对步长的数据访问周期性。我们现在基本上还是通过Audit log,达到分区的数据访问的日志,再进行步长的分析,这样就知道每一个表在特定的相对步长上面,数据访问大概是什么样一个力度或水平,帮助我们评估这张表的热度基本上是维持在什么步长范围之类,也就帮助我们判断每一张表的数据或者说哪个范围的数据是需要进行缓存,或者说我们认定为是比较热的,需要特别关注的。比如说像下面这张图,是在生产环境当中,我们可以看到它的变动范围实际上是非常稳定的。
冷热数据的处理设计思路
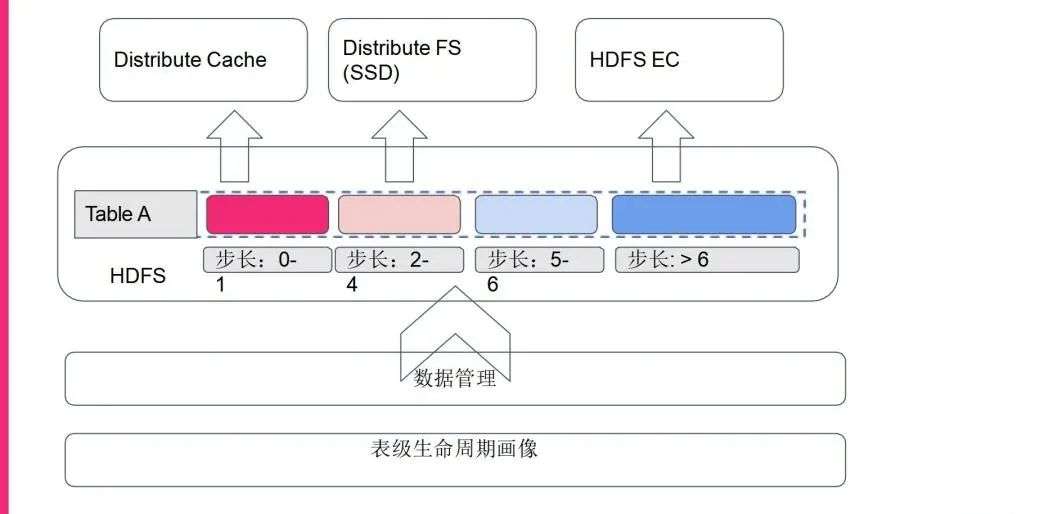
基于步长的分析思路,我们对于现在要进行的缓存进行了设计,我们希望基于现在做的表级生命周期的画像,推进数据管理。那么数据管理支配哪些表的哪些相对分区,或者说相对步长的分区,来进行缓存或相对处理?比如说它的步长大于6时,我们分析下来其实基本上是没有人访问的,那么我们就推进去做EC的数据;如果访问步长是2~4或者说5~6,我们认为是一个温热的场景,我们可以推到SSD这样的持久化存储上面去;如果说相对步长是非常小的,比如说0~1上面,访问次数如果是非常大的话,我们可能就会在一开始插入数据的时候,或者说是在比较前面的时候就会把它推到分布式缓存里面去。
缓存系统设计
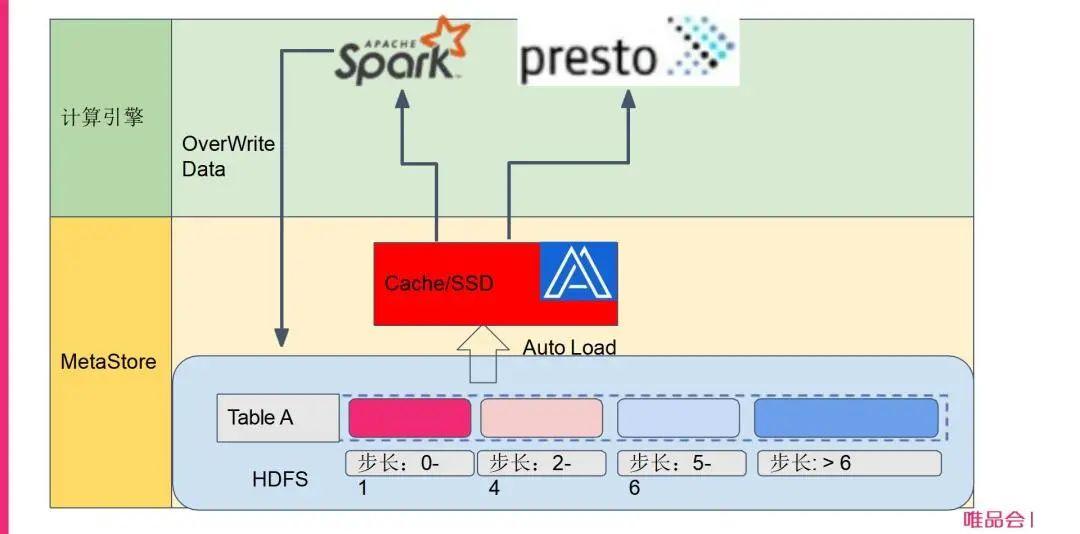
后面我们也对比了很多其他方案,我们其实也试用过 HDFS Cache这些方案,后来发现还是Alluxio Cache的支持比较全面,而且比较专注这一块。所以我们最后还是挑选Alluxio来做分布式缓存。顺便提一句,我们现在的大部分的数据ETL load已经转换为Spark了,所以我们的设计思路就是Spark写入数据的时候,就根据数据生命周期管理系统指定属性,在写入时就把数据自动化地加载到Alluxio Cache里面去,后续其他的Spark任务或者Presto的AD hoc任务,或者说其他的一些计算引擎来读取的时候,就直接能够切换到Alluxio上面进行读取,这就是我们总体的设计思路。
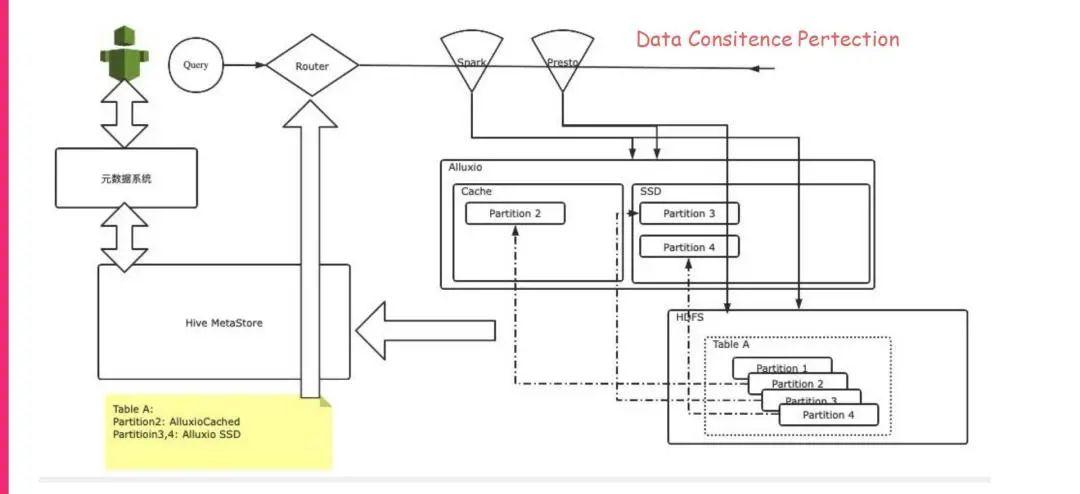
关于详细设计,我列了一下我们刚开始设计时的几张设计图,我们基本上还是会利用Hive Metastore来做最终的缓存指令或者说信息的元数据系统。ETL任务在写入的时候,也会进行 Metastore数据的读取,确定这块表或者相对步长的分区要写入Alluxio。Spark或者Presto在读的时候也会先去读 Metastore,确定这份相对步长的分区已经在Alluxio里面了,然后就会去Alluxio里面读取。
缓存写入与读取
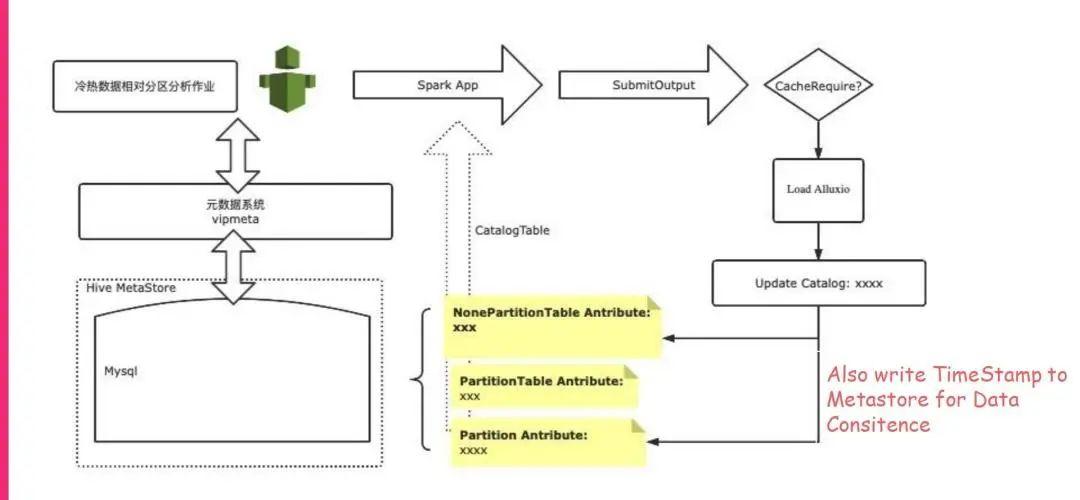
在写入的时候,这个作业在提交之后,会先去Metastore里面去读取自定义的cache的标签属性,然后确定是我们需要进行的,我们就会把这块数据落地HDFS,但是也会把它加载到Alluxio里面去,最终我们要再去修改一下Metastore,把这个Cache的属性再保存进去。
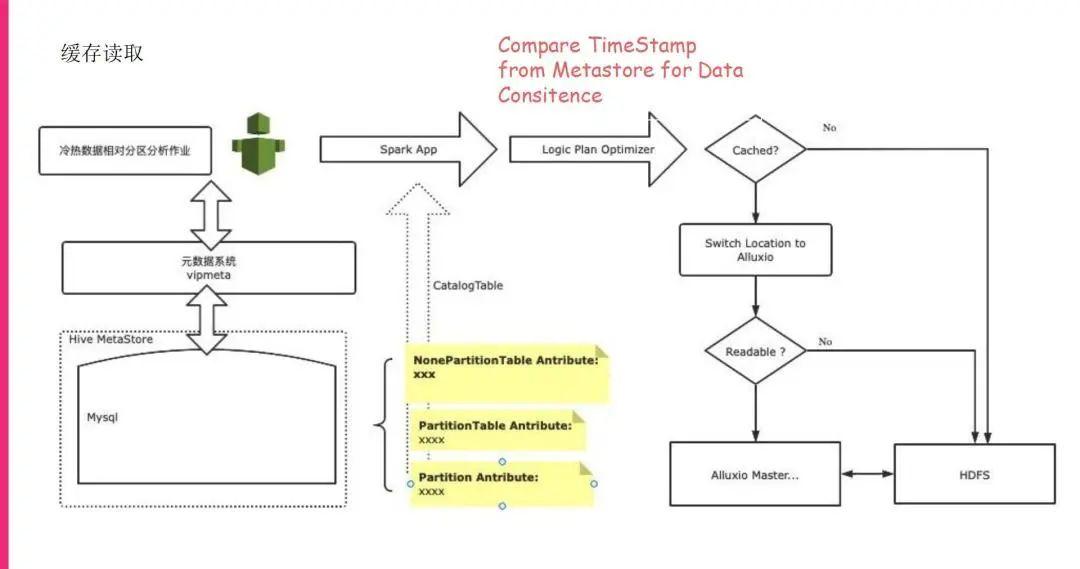
刚才提到,读取的时候也会先去读一下Metastore。我们现在的读取的切换是在逻辑执行计划优化器里面,我们自己写了一个优化来做到的,发现这块相对步长的分区已经在Alluxio里面了,那么我们就直接把访问比较自然地切换成Alluxio来进行Alluxio读取,而且Alluxio自身也是有读穿(Read-Through)功能的,可以读到底层的 HDFS数据,所以不可能会出现读不到数据的问题。
元数据接入
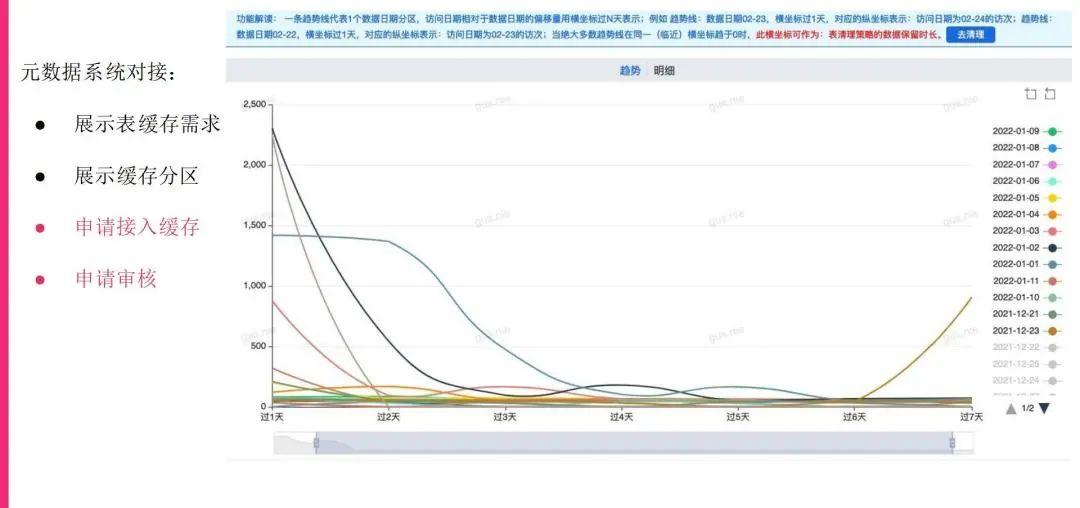
这个就是我们在读写上面的大概设计。后续我们不仅仅要做到Alluxio读写的方案,也要做到对用户透明,所以我们也需要把做了哪些分区或者相对分区,或者说建议哪些相对分区要做缓存,能够透明给用户,让用户知道。我们首先是要让每块相对步长或者相对分区的数据访问进入到我们自己的元数据系统里面,用户可以通过元数据系统明确地看到相对步长的分区和数据访问的趋势。目前我们是做到了展示表缓存需求,就是它需要缓存以及有哪些分区已经缓存了。我们还没有做的是整个申请的流程,包括审核,现在正在做,后续我们的目标就是用户可以根据这些用户数据信息,自己能申请把数据放到缓存,审核人也来审核这个申请,如果看到这个数据的访问确实是足够大的,就把它放进去。
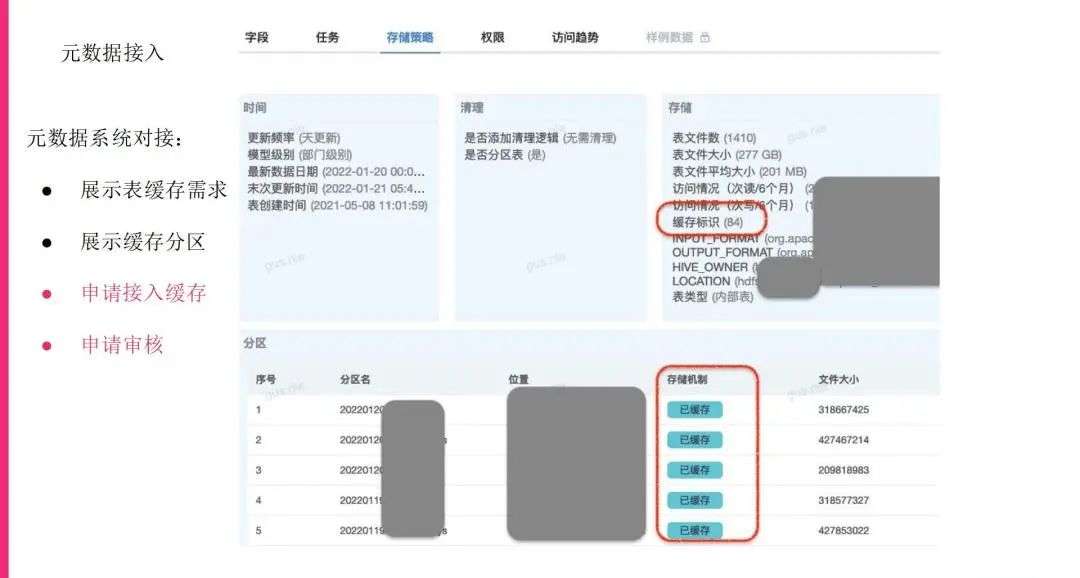
这部分就是我们数据的缓存的标识,这个标识不是个true or false,实际上就是步长的概念,就是说要放多久的相对步长的分区进去,这个表实际上是很热也是很大的,所以说它的步长是非常大的,我们这边也会标识是否放到缓存里面去。
缓存效果
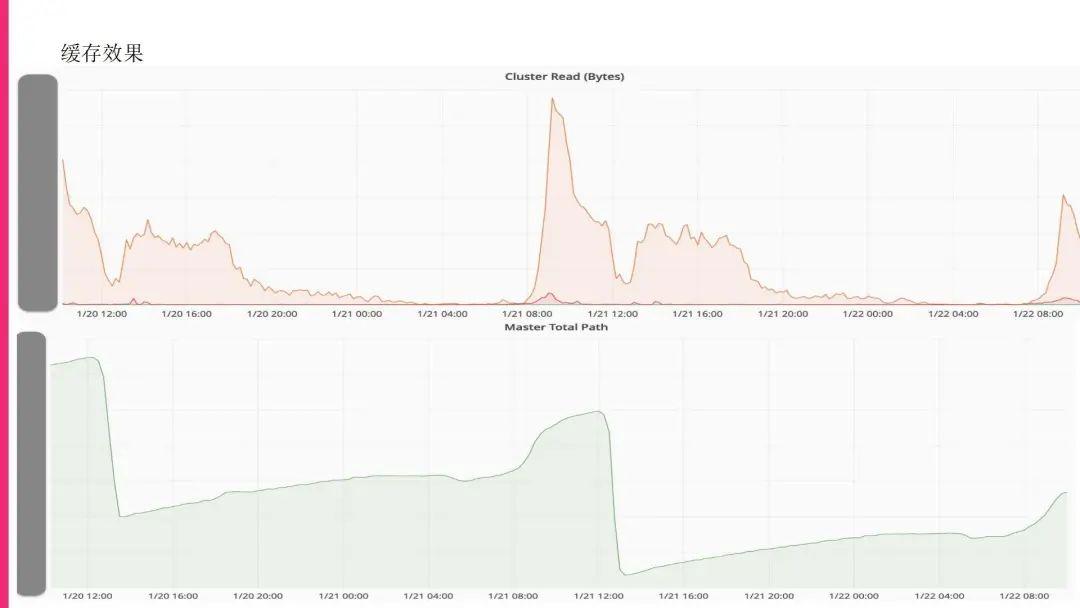
这是我们的缓存效果的展示,大家可以看到,现在上线之后基本上提供给一些 AD hoc和比较关键的作业,这些作业都是非常有特点的,就是在特定的时间会被集中性地访问,特定的时间也不是完全固定的时间,在大概的时间要不断地刷新,所以大家可以看到在特定的时间上面数据的访问,还有写入的文件path,这些在特定时间都在飙升。
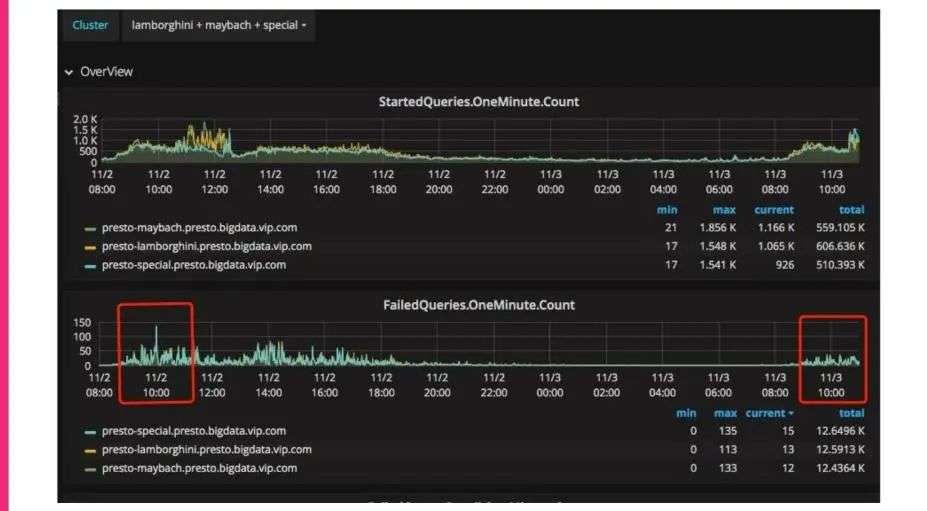
这是我们比较前端的监控,可以看到在部署了Alluxio之后,数据访问的超时率等都有非常大的缓解,后面我们还会继续推动这一块,把缓存的量慢慢地放大,把作业的量也慢慢放大。因为我们现在主要是Presto和Spark在进行这块的读取,现在统计它的效率或者效果其实不是很好统计,后续我们也希望做一些埋点,把读取这一块时间的开销单独抽取出来,方便分析。把现在读取的消耗,以及与后续上了缓存之后的消耗进行对比,这样就不用拿整个query的耗时进行对比。
加速系统-展望
Alluxio 加载数据的性能
关于后续的展望,我们现在比较关注 Alluxio在加载数据方面的性能,我们发现在某些场景下,比如一些写入比较频繁的场景下,加载的性能可能达不到我们的预期,有可能已经写进去了,很多后续查询也过来了,但这个时候Alluxio还没加载上去,所以这块也是我们要关注的。
全面使用Alluxio 接入SSD温热数据数据
还有我们现在主要是接入的Cache比较多, SSD也接入了一些, HDFS的SSD我们也是在用的,但Alluxio SSD还是要比HDFS SSD在易用性上面好很多,因为HDFS SSD操作过程比较麻烦, Alluxio这边直接就冗余了,比较方便。后续我们希望把现在比较成熟的体系,就是通过Matastore对用户透明地设置属性,然后自动加载的这套方案先从缓存开始,然后慢慢上SSD甚至上到其他的计算框架。
Alluxio Federation分流
因为我们现在的访问量是非常大的,后面如果我们要全量推开的话,我们要搭建Alluxio集群的量会比较大,目前来看我们希望还是像HDFS这样能够在元数据这边做一些切分,同时也能够分流,所以我们对Alluxio Federation是比较关注的。我们现在看到有一些公司已经做了把Alluxio接入HDFS的 Federation上面这样的方案,当然他们的方案好像没有贡献到社区里面来,我们也关注Alluxios社区自己有没有搭建Federation,或者说RBF这样的方案,或者是直接接入到HDFS。
接入其他的加速引擎方案: CK/Doris
我们也希望在加速方案里引入其他一些计算引擎,比如Doris,就是说如果这张表非常的热,我们可能希望直接就推到Doris那边去, SQL直接下推到那边去。后面我们希望这个数据服务能够直接对接到路由层,我们建立更多的路由规则,能够帮助用户更加透明地路由SQL。这就是我们系统后续的一些展望。谢谢大家!









