人工智能(AI)和机器学习工作负载依赖大型数据集,并且对数据吞吐量有较高的要求,两者都可以通过优化数据工作流来实现。
当进行AI模型训练时,我们需要高效的数据平台架构来快速生成分析结果,而模型训练在很大程度上依赖于大型数据集。执行所有模型训练的第一步都是将训练数据从存储输送到计算引擎的集群,而数据工作流的效率会大大影响模型训练的效率。
数据平台/AI平台工程师在数据架构和数据管理方面需要考虑以下几个问题:
- 数据可访问性:当数据跨越多个数据源且存储在远端时,如何高效地获取训练数据?
- 数据工作流管理:如何把数据作为工作流来管理,在训练流程中无需等待,保证数据的持续供给?
- 性能和GPU利用率:如何同时实现低元数据延迟和高数据吞吐量,确保GPU始终处于忙碌状态?
本文将针对上述端到端模型训练数据流问题,讨论一种新的方案——数据编排方案。
文章首先会分析常见的挑战和误区,然后介绍一种可用于优化AI模型训练的新技术:数据编排
AI模型训练中的常见挑战
端到端机器学习工作流是包含从数据预处理和清洗到模型训练再到推理的一系列步骤,而模型训练是整个工作流程中最重要且资源最密集的环节。
如下图所示,这是一个典型的机器学习工作流,从数据收集开始,接着是数据准备,最后是模型训练。在数据收集阶段,数据平台工程师通常需要花费大量的时间来确保数据工程师能够访问数据,之后数据工程师会对数据科学家搭建和迭代模型所需的数据进行准备。

训练阶段需要处理海量的数据,确保GPU能够持续获取数据,从而生成训练模型。因此我们需要对数据进行管理,使其能够满足机器学习的复杂性及其可执行架构的需求。在数据工作流中,每个步骤都面临相应的技术挑战。
数据收集上的挑战——数据无处不在
数据集越大,越有助于模型训练,因此收集所有相关数据源的数据至关重要。当数据分布在本地、云上或者跨区域的数据湖、数据仓库和对象存储中时,将所有的数据集中成单一数据源的做法不再可行。鉴于数据孤岛的存在,通过网络远程访问数据难免会造成延迟。如何在实现所需性能的同时确保数据可被访问成为巨大的挑战。
数据准备上的挑战——串行化的数据准备
数据准备从收集阶段的数据导入开始,包括数据清洗、ETL和转换,最后再将数据用于模型训练。如果孤立地考虑这个阶段,则数据工作流是串行化的,训练集群在等待数据准备的过程中会浪费大量时间。因此,AI平台工程师必须想办法创建并行化的数据工作流,实现数据的高效共享和中间结果的有效存储。
模型训练上的挑战——受制于I/O且GPU利用率低
模型训练需要处理数百万亿字节的数据,但通常是图像和音频文件等海量小文件。模型训练需要多次运行epoch来进行迭代,因此会频繁地访问数据。此外, 还需要通过不断向GPU供给数据来让GPU处于忙碌状态。既要优化I/O又要保持GPU所需的吞吐量并非易事。
传统方案和常见误区
在讨论不同的解决方案之前,我们先来看一个简化的场景,如下图所示:
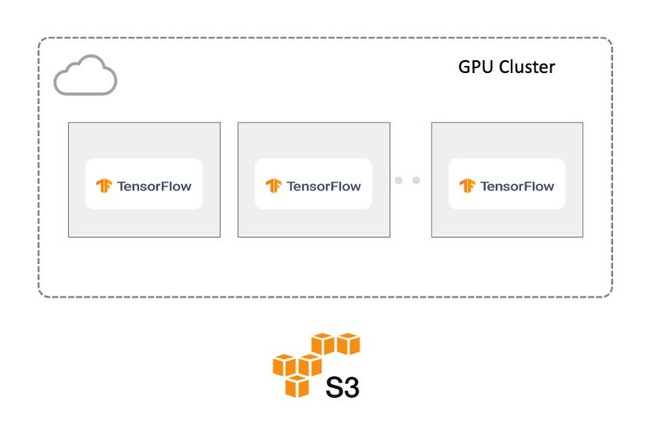
我们在云上使用一个多节点的GPU集群,并把TensorFlow作为机器学习框架来进行模型训练。预处理的数据存储在亚马逊S3中。一般来说,让训练集群获取这些数据有两种方案,我们接下来会分别讨论:
方案一:把数据拷贝到本地存储
第一种方案如下图所示,将远端存储中的完整训练数据集拷贝到每个用于训练的服务器的本地存储中。这样可保证数据的本地性,训练作业实际上是从本地读取数据,而非远程访问数据。
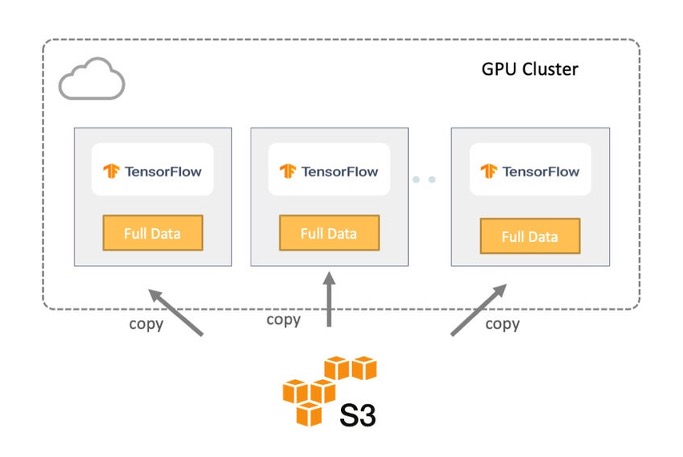
从数据工作流和I/O的角度来看,由于所有数据都在本地,因此该方案能够达到最大的I/O吞吐量。除了一开始训练必须等待数据完全从对象存储拷贝到训练集群外,GPU会始终处于忙碌状态。
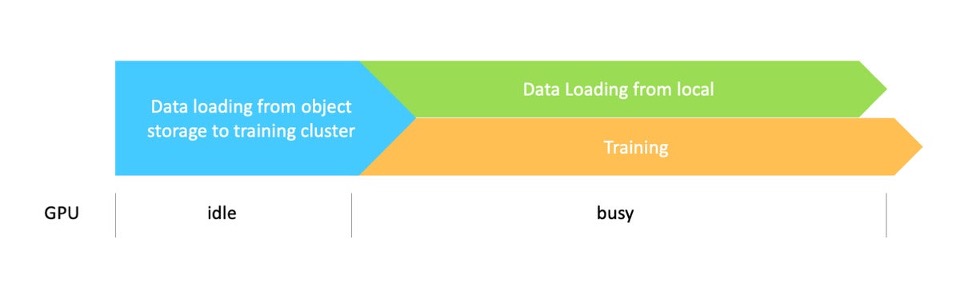
尽管如此,该方案并不适合所有情况。
首先,数据集的大小必须匹配本地存储的总容量。随着输入数据集的增大,数据拷贝耗时越来越长且更容易出错,与此同时也造成了GPU资源的浪费。
其次,将大量的数据拷贝到每台训练机上,会给存储系统和网络带来巨大的压力。在输入数据经常变化的情况下,数据同步可能会非常复杂。
最后,手动拷贝数据既费时又容易出错,因为要保持云存储上的数据与训练数据同步非常困难。
方案二:直接访问云存储
另一种常见的方案如下图所示,让训练作业直接远程访问云存储上的目标数据集。如果采用该方案,数据集的大小就不再成为限制,但也面临着几个新的挑战:
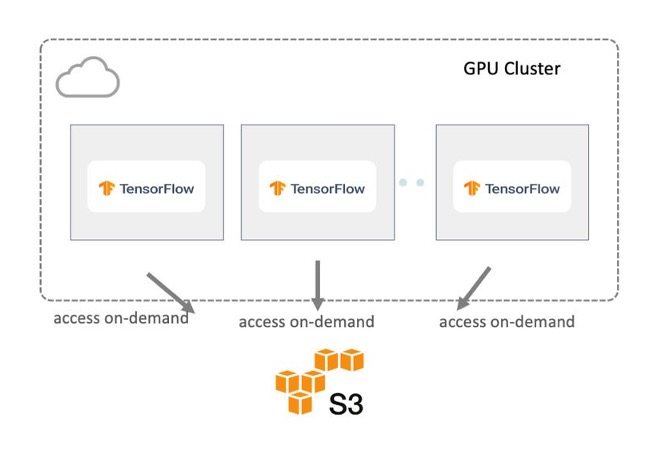
首先,从I/O和工作流的角度来看,数据是串行处理的,所有的数据访问操作都必须通过对象存储和训练集群之间的网络,这使得I/O成为性能瓶颈。由于I/O操作的吞吐量受限于网络速度,GPU会出现空转等待的情况。
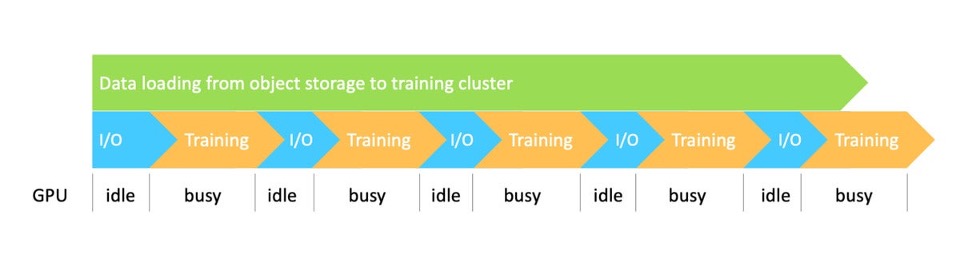
其次,当训练规模较大时,所有训练节点需要同时访问同一个云存储中的同一个数据集,会对云存储系统造成巨大的负载压力。此时由于高并发访问,云存储很可能会出现拥塞,导致GPU利用率低。
最后,如果数据集由海量小文件组成,元数据访问请求将占到数据请求的很大一部分。因此,直接从对象存储获取大量文件或目录的元数据操作将成为性能瓶颈,同时也会增加元数据操作成本。
推荐方案——数据编排
为了应对这些挑战和误区,我们需要重新考虑针对机器学习工作流I/O的数据平台架构。这里,我们推荐采用数据编排来加速端到端的模型训练工作流。数据编排技术将跨存储系统的数据访问抽象化,把所有的数据虚拟化,并通过标准化的API和全局命名空间为数据驱动型应用提供数据。
通过抽象化统一数据孤岛
该方案不拷贝和移动数据,无论是在本地还是在云上的数据都留在原地。通过数据编排技术,数据被抽象化从而呈现统一的视图,大大降低数据收集阶段的复杂性。
由于数据编排平台已经实现与存储系统的集成,机器学习框架只需与数据编排平台交互即可从其连接的任何存储中访问数据。因此,我们可以利用来自任何数据源的数据进行训练,提高模型训练质量。在无需将数据手动移动到某一集中的数据源的情况下,包括Spark、Presto、PyTorch和TensorFlow在内所有的计算框架都可以访问数据,不必担心数据的存放位置。
通过分布式缓存实现数据本地性
我们建议采用分布式缓存,让数据均匀地分布在集群中,而不是将整个数据集复制到每台机器上。当训练数据集的大小远大于单个节点的存储容量时,分布式缓存尤其有用,而当数据位于远端存储时,分布式缓存会把数据缓存在本地,有利于数据访问。此外,由于在访问数据时不产生网络I/O,机器学习训练速度更快、更高效。
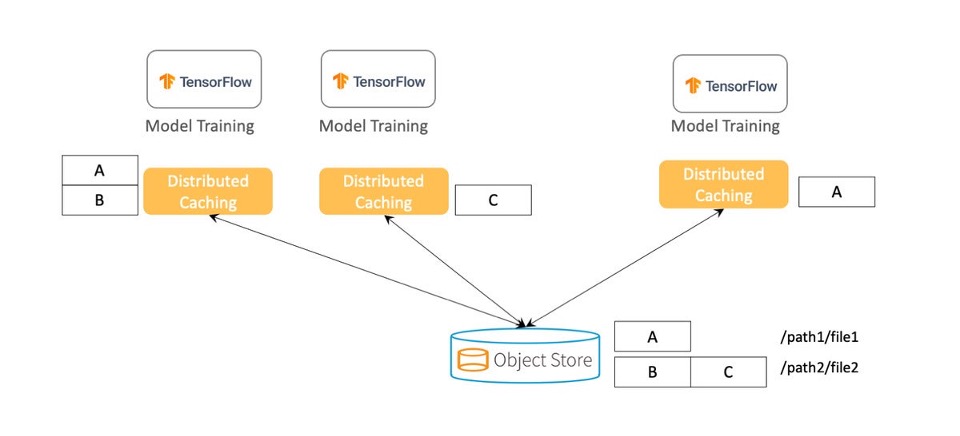
如上图所示,对象存储中存有全部训练数据,两个文件(/path1/file1和/path2/file2)代表数据集。我们不在每台训练节点上存储所有文件块,而是将文件块分布式地存储在多台机器上。为了防止数据丢失和提高读取并发性,每个块可以同时存储在多个服务器上。
优化整个工作流的数据共享
在模型训练工作中,无论是在单个作业还是不同作业之间,数据读取和写入都有很大程度的重叠。数据共享可以确保所有的计算框架都可以访问之前已经缓存的数据,供下一步的工作负载进行读取和写入。比如在数据准备阶段使用Spark进行ETL,那么数据共享可以确保输出数据被缓存,供后续阶段使用。通过数据共享,整个数据工作流都可以获得更好的端到端性能。
通过并行执行数据预加载、缓存和训练来编排数据工作流
我们通过实现预加载和按需缓存来编排数据工作流。如下图显示,通过数据缓存从数据源加载数据可以与实际训练任务并行执行。因此,训练在访问数据时将得益于高数据吞吐量,不必等待数据全部缓存完毕才开始训练。
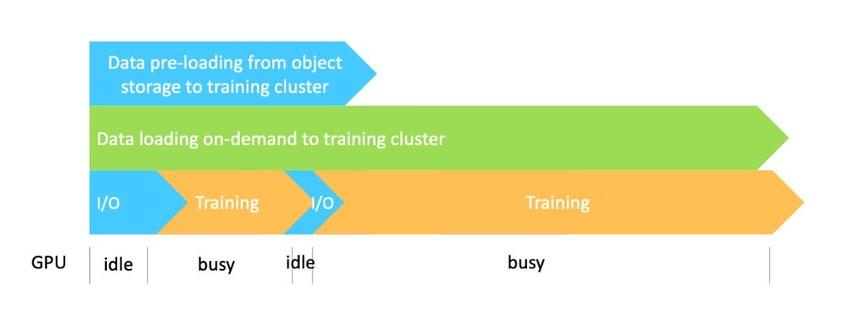
虽然一开始会出现I/O延迟,但随着越来越多的数据被加载到缓存中,I/O等待时间会减少。在本方案中,所有环节,包括训练数据集从对象存储加载到训练集群、数据缓存、按需加载用于训练的数据以及训练作业本身,都可以并行地、相互交错地执行,从而极大地加速了整个训练进程。
现在我们来看看新方案与两种传统方案的对比情况。通过对机器学习工作流各个步骤所需的数据进行编排,我们避免了数据在不同阶段的串行化操作以及随之而来的低I/O效率,也提高了GPU利用率。
如何对机器学习工作负载进行数据编排
这里我们以Alluxio为例来介绍如何使用数据编排。同样,我们还是看这个简化的场景,这里可以使用Kubernetes或公有云服务来调度TensorFlow作业。
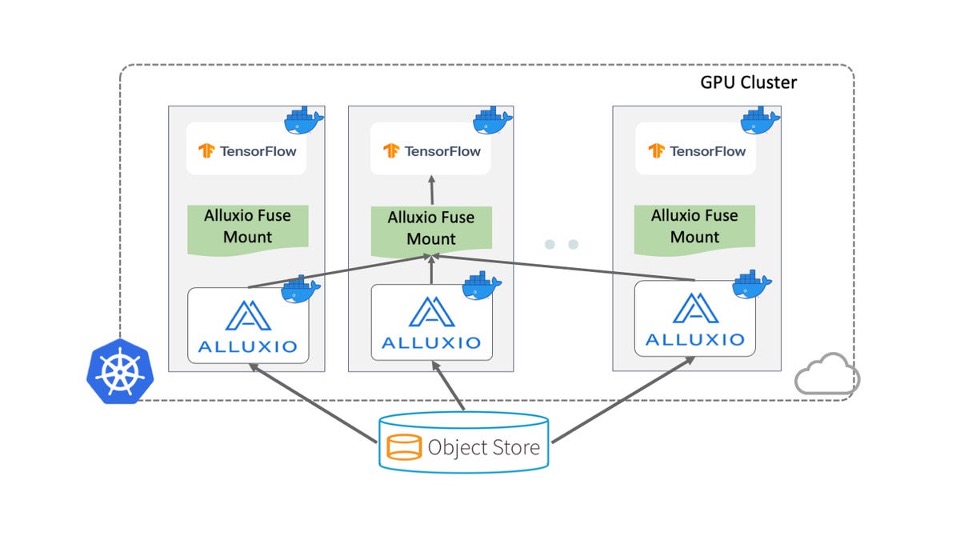
使用Alluxio来编排机器学习和深度学习训练通常包含以下三个步骤:
- 在训练集群中部署Alluxio;
- 将Alluxio服务挂载至训练节点的本地文件目录;
- 使用训练脚本, 从Alluxio服务的挂载点访问缓存在Alluxio以及底层存储中的数据
Alluxio挂载完成后即可通过Alluxio访问不同存储系统中的数据,此时可使用基准测试脚本来透明地访问数据,无需修改TensorFlow。相较于需要整合每个特定的存储系统以及配置证书的常规操作,这大大简化了应用的开发过程。
您可以点击查看参照指南,使用Alluxio和TensorFlow运行图像识别。
数据编排的最佳实践
鉴于任何方案都不能适用于所有场景,我们推荐在下述条件下使用数据编排:
- 您需要进行分布式训练;
- 您有大量的训练数据(>= 10 TB),尤其是训练数据集中包含海量小文件/图像;
- 网络 I/O 速度不足以让您的 GPU 资源始终处于忙碌状态;
- 您的工作流涉及多个数据源和多个训练/计算框架;
- 您希望在能够满足额外训练任务需求的同时依然保持底层存储系统稳定;
- 多个训练节点或任务共享同一个数据集。
随着机器学习技术不断发展以及框架执行的任务愈加复杂,我们管理数据工作流的方法也将不断优化。通过在数据工作流中使用数据编排技术,端到端训练工作流可以实现更高的效率和资源利用率。
Reprinted with permission. IDG Communications, Inc., 2022. All rights reserved.









