一、关于“韩国头部电商平台”(以下简称“C”)
“C”是韩国本土的电商巨头,常被称为“韩国的亚马逊”,其业务及服务涵盖多个领域。作为韩国领先的电商平台,“C”的技术架构是其能够提供快速配送和高效电商服务的核心之一,技术架构不仅支持着高效的物流配送,还通过精确的个性化推荐和智能化运营提升了整体用户体验。随着市场需求不断增长,“C”的技术平台也在持续升级和优化,旨在应对日益增加的挑战和业务需求。
二、背景:
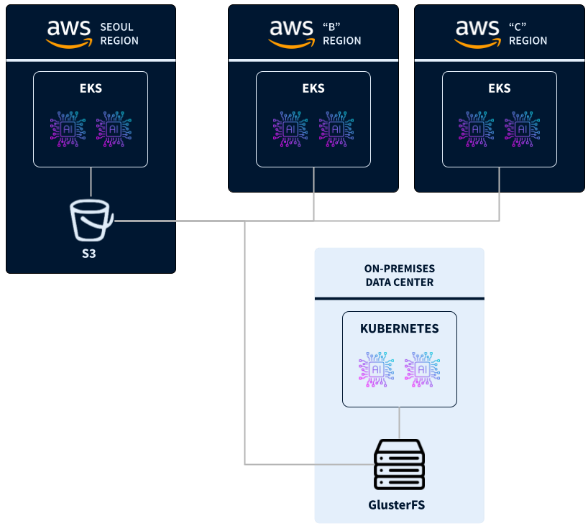
为了提高产品搜索精度和个性化推荐,优化用户体验并提升运营效率,“C”一直将AI/ML视作其核心竞争力之一,最初,“C”的数据主要存储在首尔区域的AWS,并集中在该区域的GPU集群进行训练。随着数据量的增长和计算需求的提升,“C”逐步将GPU训练工作负载扩展到本地数据中心和其他区域(如美西),形成了以首尔为中心的大规模数据湖,支持跨区域的数据访问。然而,随着数据量达到数百PB的规模后,“C”在多个区域的AWS和本地数据中心面临存储和网络带宽瓶颈,导致训练任务变得缓慢且不稳定。
三、主要挑战包括:
- 高昂的AWS S3 API调用和Egress费用:随着数据量的增加,“C”在AWS S3上的API调用和流量费用不断攀升,给公司带来了较大的成本压力。
- GPU利用率低:由于数据传输的延迟和存储瓶颈,GPU资源未能得到充分利用,训练任务的效率低下,延长了模型训练时间。
- GlusterFS管理复杂性:“C”使用Gluster FS进行本地存储,但其硬件和软件的管理成本高,且需要专门的运维人员维护,增加了公司的运维复杂性。
四、Alluxio的解决方案
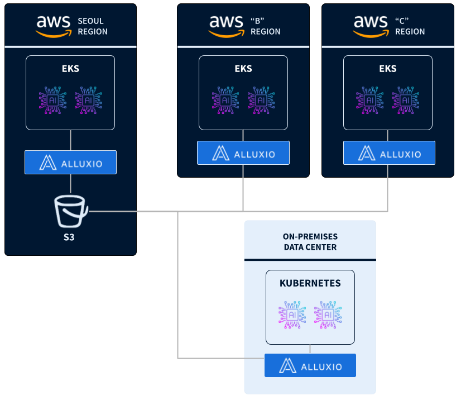
为了解决这些技术瓶颈,“C”评估了多个高性能存储解决方案,最终选择了Alluxio Enterprise AI。Alluxio以其创新的分布式缓存技术脱颖而出,能够显著提高数据访问速度,优化训练任务的执行效率。通过部署Alluxio,“C”能够缓解存储和网络带宽的限制,实现了更快、更稳定的AI/ML训练任务。
“C”在每个AWS区域以及本地数据中心都部署了Alluxio分布式缓存集群,同时将其单一真实数据源(即核心数据集)继续存储在首尔区域的AWS S3中。通过Alluxio的分布式缓存架构,数据可以被快速缓存并分发到不同计算节点,避免了频繁的S3访问,从而降低了成本并提高了数据处理效率。
五、紧密合作与优化
“C”与Alluxio团队密切合作,确保在多个团队之间实现高效的数据共享与协作。具体措施包括:
- 多租户管理:通过Space Quota Management(空间配额管理),确保了高优先级团队(如搜索团队)可以获得足够的资源,同时不影响其他团队的性能体验。这种分级权限管理让不同团队在使用Alluxio时,能够保证资源的公平分配和高效利用。
- 异构节点支持:为了支持不同硬件配置,Alluxio能够在同质化节点与定制化节点之间灵活切换,满足“C”在不同计算节点上的需求。
- 工作流优化:在本地数据中心,“C”的AI/ML工作流曾面临503错误和冷数据加载的问题。通过与“C”的算法团队和基础设施团队共同讨论,Alluxio优化了工作流,包括提前执行分布式负载、开启集群级别的限流等策略,进一步提高了系统的稳定性和效率。
- 运维的迭代:
- Vertical Auditing-哪些数据集最被频繁使用-通过Prometheus查看到3-5级别目录;热数据的访问虽然只缓存一次也可以被更好的追踪。
- TTL 从全局变为不同的Directory或者是数据集的 TTL, 不同用户组可以自己设定TTL
六、价值与收益
自从部署Alluxio Enterprise AI后,“C”的AI/ML训练工作负载得到了显著改善。具体收益如下:
- 将AWS S3 API调用和Egress费用降低了50%以上:通过Alluxio的分布式缓存,“C”减少了S3的数据访问频次,从而大幅降低了API调用和流量费用。
- GPU利用率提升30%:Alluxio加速了数据的读取过程,使GPU在训练过程中的利用率得到了大幅提升,提升了训练任务的整体吞吐量。
- 降低了本地数据中心的运维复杂性:Alluxio的自动化运维和简化的存储管理,使得“C”减少了对传统存储系统(如GlusterFS)的依赖,降低了运维成本。
七、后续规划
“C”计划进一步扩展其AI/ML训练平台,推动跨团队的多租户数据缓存服务,具体规划包括:
- 建立支持多租户的数据缓存平台:该平台将支持多个团队(如搜索、推荐、广告等)之间的数据共享,并提供灵活、高效的数据加速服务。
- 进一步简化存储管理:去除GlusterFS等传统存储系统,降低软硬件采购和运维成本。
- 细颗粒度的流量监控与优化:通过进一步细化跨域出口流量的监控与分析,实现更精准的成本优化。
- 持续提升性能:进一步支持RDMA(远程直接内存访问)和GDS(GPU直接存储)技术,以持续提升数据处理和训练任务的性能。









