专为AI/ML设计的解决方案,让您可以随时随地无缝访问、管理和运行AI/ML工作负载。
为保持竞争力并在竞争中脱颖而出,各家企业都在全力推进数据和AI基础设施的现代化。在此过程中,企业家们也意识到传统的数据基础设施已经无法匹配下一代数据密集型AI负载的需求。在AI项目推进中经常遭遇各类挑战,诸如性能低下、数据可访问性差、GPU稀缺、数据工程复杂以及资源未充分利用等,都严重妨碍了企业获取数据价值。Gartner研究称:“可操作AI的价值在于能够在企业的各种环境下进行快速开发、部署、调整和维护。考虑到工程复杂性和更快的市场响应需求,开发较为灵活的AI工程数据流,构建能够在生产中进行自适应的AI模型均至关重要” ,“到 2026 年,采用AI工程来构建和管理自适应AI系统的企业,将在AI模型可操作性方面至少超越同行 25%。”
Alluxio Enterprise AI 拥有去中心化元数据的分布式系统架构,可消除访问海量小文件(常见于AI 负载)时的性能瓶颈。无论文件大小或数量如何,都能确保具备超越传统架构的无限扩展性。与传统分析不同,分布式缓存是根据AI负载I/O模式量身定制的。此外,还支持分析负载以及从数据摄取到ETL(提取、转换、加载)、预处理、训练和服务的完整机器学习工作流 。
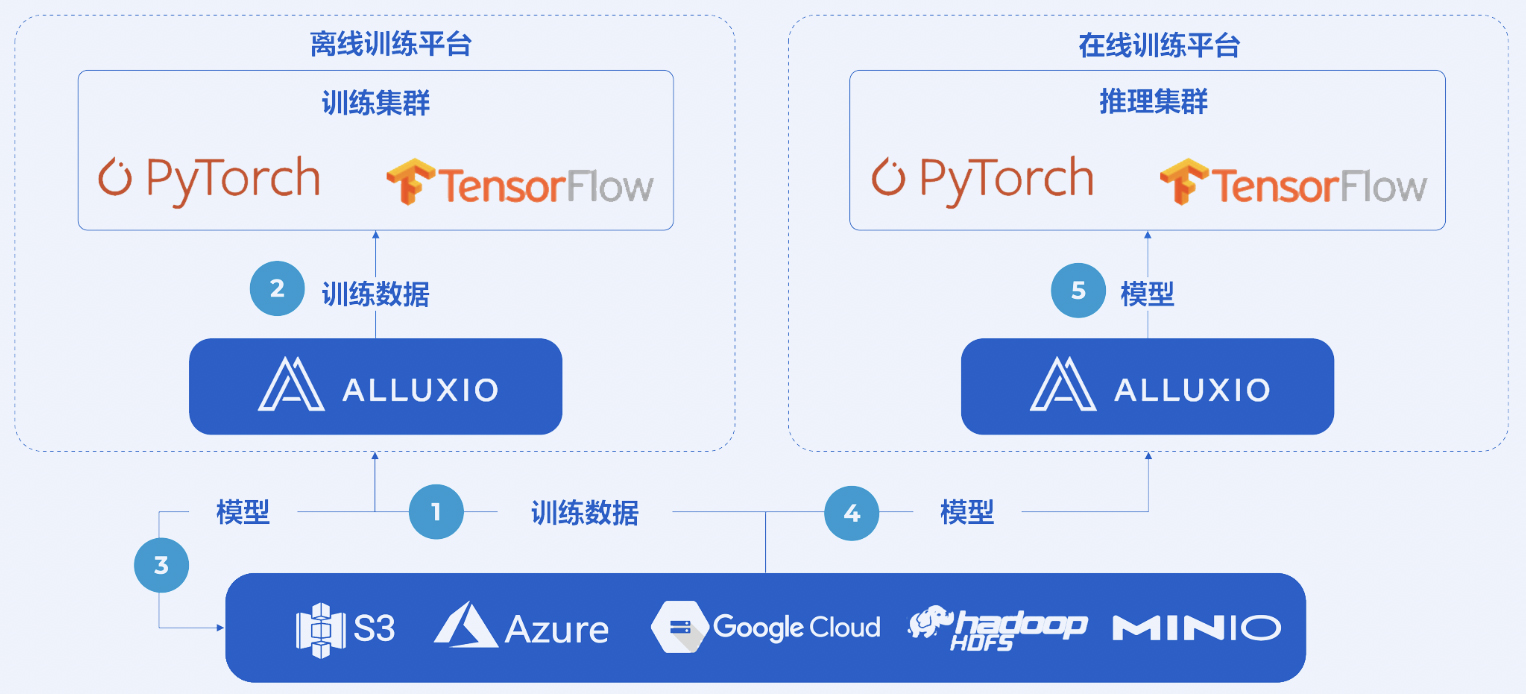
Alluxio Enterprise AI可以添加到由AI计算引擎和数据湖存储组成的已有AI基础设施中。Alluxio 位于计算和存储中间,可以在机器学习工作流中跨模型训练和模型服务工作,从而实现最大速度和最优成本。例如,将PyTorch作为训练和服务引擎, Amazon S3为现有数据湖:
模型训练:
当用户训练模型时,PyTorch数据加载器从虚拟本地路径/mnt/alluxio_fuse/training_datasets加载数据集。数据加载器不会直接从 S3 加载数据,而是从 Alluxio 缓存加载。在训练过程中,缓存的数据集将在多个epoch中使用,因此整个训练速度不再受制于访问S3而产生的瓶颈。也就是说,Alluxio通过缩短数据加载来加速训练,消除GPU空闲等待时间,提高GPU利用率。模型训练完成后,PyTorch通过Alluxio将模型文件写入S3。
模型服务:
最新训练的模型需要部署到推理集群。多个TorchServe实例同时从S3并发读取模型文件。Alluxio会缓存这些来自S3的最新模型文件,并以低延迟提供给推理集群。因此,最新模型一旦可用时,下游的AI应用即可将其用于推理。
预期训练速度可比使用商业化对象存储快20倍,模型服务速度提升高达10倍,GPU利用率达90%以上,AI 基础设施成本节约高达90%。
《PyTorch 模型训练性能调优宝典》
《为企业生产环境下的AI负载选择合适的架构》
《大模型制胜宝典——解密AI高效数据访问策略》