
分享嘉宾:
孙颢宁
Shopee Data Infra
分布式存储开发工程师
分享大纲:
在打造 AI 平台前,不同部门的算法团队都需要自己去申请购买云服务,资源利用率低。公司决定搭建训练机房,构建 AI 平台。我们开发 AI 平台面临的如下几大挑战:
数据是驱动 AI 技术发展的重要基础。随着 AI 技术的不断发展,训练模型所需的数据量也在迅速增加,从数百GB到TB级别不等,需要有效地存储和管理这些数据。
在分布式训练环境中, 数据传输要求高效的协议以及带宽管理来做支撑,训练过程中会有大量读写,可能导致 I/O 瓶颈,从而影响训练速度。
AI 平台面向所有算法开发人员,会运行大量任务,此时,高效的任务调度变得极为重要,需要它来保证任务的负载均衡,同时需要确保计算资源和存储资源的高效利用。
数据存储方面,训练的原始数据是存储在 HDFS 上的,AI 平台还会使用对象存储。任务调度和资源分配则主要受益于云技术的发展。
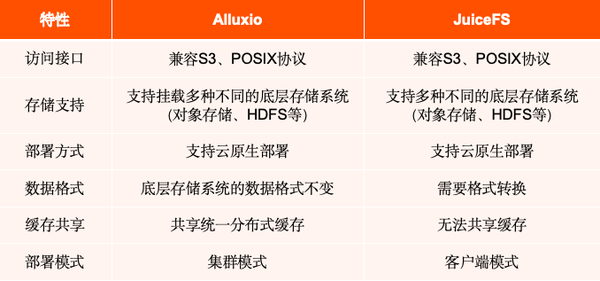
加速数据访问训练方面,AI 平台主要做了目前市面上的两个主流工具的调研:Alluxio 和 JuiceFS,它们分别有图上所示特性。
基于 AI 平台的架构设计需求,目前 Alluxio 能够较好覆盖这些需求,所以 AI 平台最终选择了 Alluxio 作为缓存加速层。
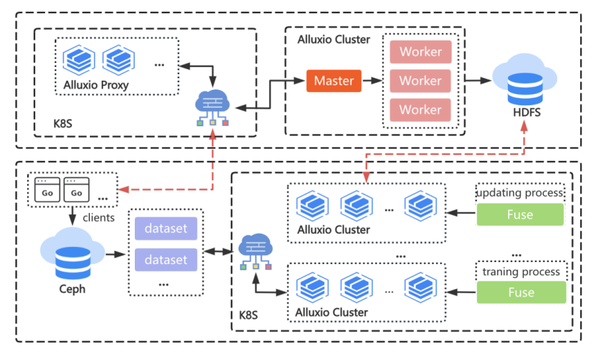
在 AI 平台的整个调度与训练流程中,Alluxio 贯穿了数据准备、训练以及数据更新多个阶段。下面是具体的架构图,图中上半部分是 DI 部门的 Alluxio 集群,底层存储是 HDFS,下半部分是 AI 平台集群。
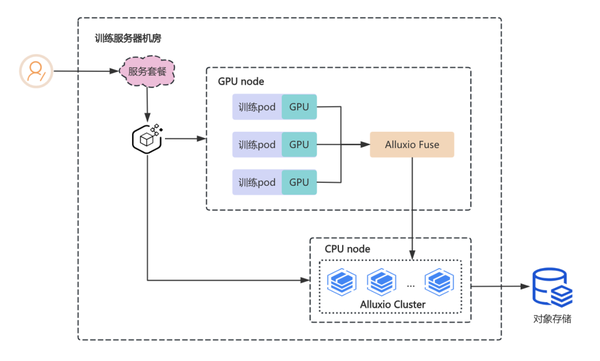
再来看一下 AI 平台的架构。整个 AI 平台采用云原生架构,方便进行资源调度与服务部署。
我们已经看到 Alluxio 贯穿了整个训练周期,在大量使用 Alluxio 的过程中,我们在某些特定的场景下遇到了一些性能问题。
在上一次关于 Alluxio 的分享当中,我介绍过一部分场景下的优化,包括快速加载元数据、如何保证 load 数据被完全缓存、并发读性能的优化等。
我们继续来看一下FUSE 并发访问的性能问题,在 AI 平台使用 dataset 库去 load 数据的时候,多线程并发相较于单线程读性能出现了急剧下降。
出现这个问题,是因为 libfuse 对” page cache “的使用与文件描述符有关,而 Alluxio-FUSE 会为并发读取同一文件的不同线程分配不同的文件描述符,影响了读性能。
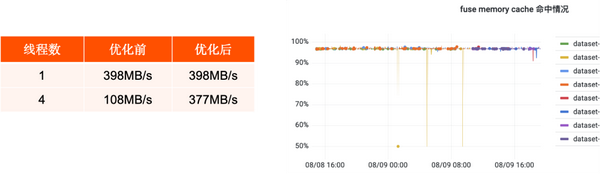
在这种场景下,先为 FUSE 配置了 Memory cache,从右边这幅图可以看到,在顺序读的时候,缓存命中率在 95% 以上。然后为并发读同一个文件的线程使用相同的文件描述符,这样在 FUSE 中使用相同的数据流,可以共享 memory cache,来提高并发读的性能。左边的表格是测试结果,在优化前,四线程相较于单线程读性能下降了近 4 倍,在优化之后,四线程的读取效率相较于单线程,性能损失是很少的。由此我们解决了在多线程并发读引起的性能下降问题。
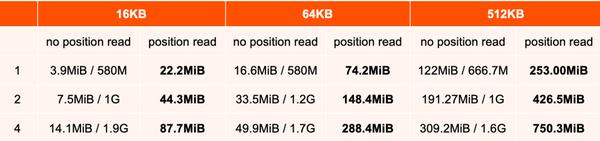
上面介绍了顺序读的问题,再来看一下随机读的情况,对 LLM 数据集的训练过程,涉及大量随机读操作,会导致读性能下降。还有一个读放大的问题,因为 Alluxio 的 client 端在读数据时,会读取一个 block 块大小,这样就会读取到非常多冗余数据,造成读放大问题。
在缓解读放大问题时,AI 平台开始的做法是将 block size 调小到 4MB,但是这样会导致元数据膨胀。为此,我们为FUSE 实现了 position read。下面是 AI 平台给出的随机读的性能测试,在没有使用 position read 的情况下,随机读的数据量越小,性能越差,读放大的问题越严重。在使用 position read 的情况下,可以完全解决读放大问题,并将读性能提升了 2~7 倍。还有一个好处就是,block size 的大小可以调整到更大,减少元数据的数量。
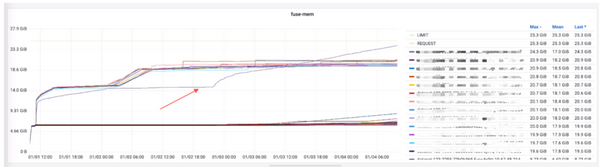
在训练 LLM 数据集时,有时会出现 OOM 的问题,因为 LLM 数据集有两个特点:
随着训练时间的延长,FUSE 的内存使用逐渐增加,最终接近容器内存配额,触发了 OOM-killer 机制,导致 FUSE 异常关闭。上图可以看到其中一个数据集的 FUSE 内存使用量是在缓慢增加的。
我们分析这个问题可能和 netty 使用直接内存的配置或者是 glibc 的内存分配策略有关。于是,我们测试了两种解决方案:
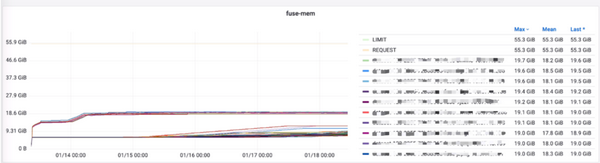
上图所示,在优化之后,所有的任务没有再出现 OOM 的问题。AI 平台还进行了两阶段测试,限制 netty 内存之后,内存占用稳定在 24GB 左右;同时使用 tcmalloc,内存占用稳定在 20GB 左右。
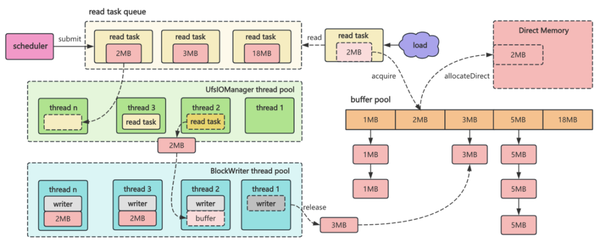
在训练之前,AI 平台会预热数据,把数据加载到 Worker 上,Alluxio 提供了 load 方法来加载数据的。如果加载数据量比较小或者给 Worker 分配大内存,运行是没什么问题的。一旦遇到大数据集,需要我们在性能、稳定性、资源利用率上做平衡的时候,就容易出现一些问题。结合上图,我们遇到了三个问题:
那么我们是如何解决的呢?
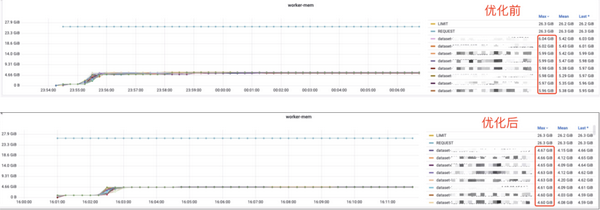
上图为优化前后的对比,优化之前一个 load 任务最大需要内存大约在 6GB 左右,优化之后,(此处优化指将 buffer 申请推迟到运行时)整体最大内存需求在 4.6GB 左右,这样可以节省约 25% 的内存占用。而在 read 和 write 在同一个线程中运行,使 AI 平台可根据线程数来估算内存分配量,没有再出现 OOM 异常。
我们再来看一下内存分配的解决方案
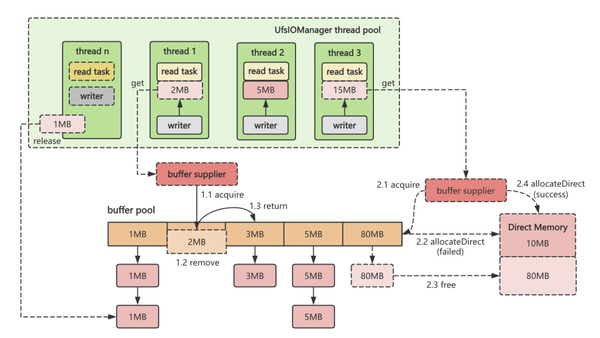
在加载数据集文件较大时,可能这两处改动影响不大。因为加载一个大文件所需 buffer 大小大部分是 block 的大小。但是在预热千万级混合大小文件的场景中,可节省超过 50% 的内存,资源能够得到更好的利用。
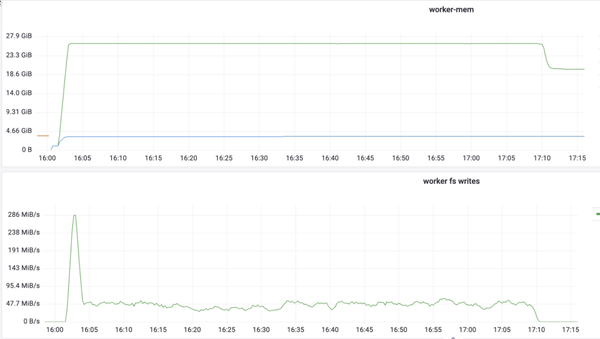
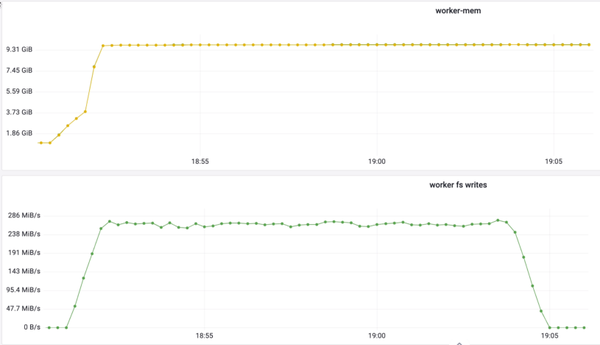
上面我们介绍 worker 在 load 数据时有两部分操作:读和写。我们发现写过程出现了性能下降。如上图下半部分,刚开始写的时候写速度急速上升后又会急速下降,下降到一定数值之后在一定范围内波动。与此同时我们观察到它和 worker 的 memory 使用相关度是非常高的,我们可以看到上图上半部分中,worker 的 memory 在使用达到最高点,写的速率也是最高的,之后它就会急剧下降。于是怀疑与 page cache 有关,当页缓存达到内存限制时,操作系统需要动态管理页缓存中的数据,写入操作需要等待页缓存中的数据被写入磁盘,从而引入额外的延迟。
为了解决这个问题,决定尝试绕过页缓存,直接使用 Direct I/O 的方式,将数据直接写入磁盘。下图为使用 Direct I/O 的效果,写的速度达到峰值后能一直保持这个速度,对于测试任务,写的整体速度有 5~6 倍的提升。并且内存的使用也降低了很多。
使用 Direct I/O ,有三点要注意:
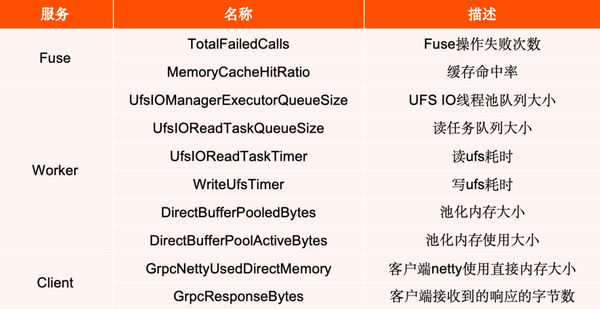
我们能够发现并解决上面问题,得益于我们配置了丰富的监控指标,图表里列举了一部分我们自己添加的 metrics,增加更多的指标有助于更全面地监控任务运行状态,从而更有效地识别和排查性能问题。
上述优化均基于 Alluxio 2.9 版本完成,并且提供给 AI 平台的也是这一版本。
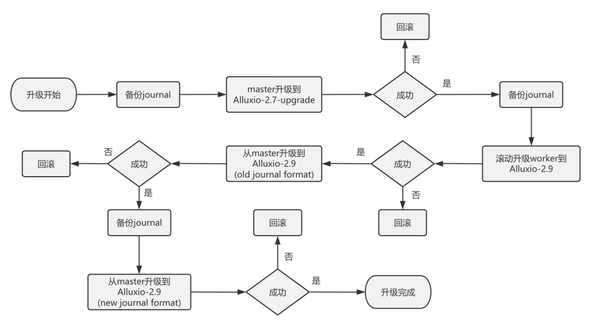
目前,DI 内部的 Alluxio 集群是 2.7 版本,而 AI 平台则使用了 2.9 版本。为简化运维并避免同时维护多个分支,我们计划将 Alluxio 从 2.7 版本升级至 2.9 版本。下面简要概述我们在升级过程中所做的准备工作:
在升级 Alluxio 的过程中,备份 journal 是至关重要的一步。因为 journal 包含了 Alluxio 元数据,确保了在升级过程中如果需要回滚,服务可以恢复到正常运行状态。我们首先会备份 journal,然后将 master 节点升级到一个基于 2.7 版本的特殊 upgrade 分支,该分支已经整合了所有为此次升级所做的准备工作,并且与主分支保持独立。一旦确认 master 节点升级成功并稳定运行后,我们将再次备份 journal。随后,逐步将 Alluxio Worker 节点升级至 2.9 版本。
在验证升级后的 Worker 节点成功运行后,我们将 master 节点升级到 2.9 版本,并继续使用旧的 journal 格式。待服务验证无误,我们将切换至新的 journal 格式。到这里,整个服务的升级就完成了。尽管升级步骤相对简单,但整个升级周期较长,因为每次升级后都需要一段时间来观察服务的稳定性和功能表现,以确保一切正常运行。由于前期进行了大量的验证和充分的准备工作,升级过程得以一次性顺利完成。
接下来介绍一下我们的未来规划,分为两部分,一个是 AI 平台,另一个是 Alluxio 服务。
数据处理模块使用 Alluxio-3.x 的 FUSE 替换 Cluster 模式;
model / checkpoint 读写优化;
探索 Alluxio 支持更大规模(文件数大于2000w,数据量大于25TB)的训练。
通过使 S3-Proxy 直接访问 UFS 数据源,绕过 Worker 节点,减少带宽占用;
通过改进和优化 Alluxio-3.x 的 FUSE,将其开发为稳定且易用的文件工具;
优化 Alluxio Cluster 的元数据一致性问题;
升级到 Dora 架构。
在当前的技术环境下,搜索、推荐、广告、大模型、自动驾驶等领域的业务依赖于海量数据的处理和复杂模型的训练。这些任务通常涉及从用户行为数据和社交网络数据中提取大量信息,进行模型训练和推理。这一过程需要强大的数据分发能力,尤其是在多个服务器同时拉取同一份数据时,更是考验基础设施的性能。

南方科技大学是深圳在中国高等教育改革发展的时代背景下创建的一所高起点、高定位的公办新型研究型大学。2022年2月14日,教育部等三部委公布第二轮“双一流”建设高校及建设学科名单,南方科技大学及数学学科入选“双一流”建设高校及建设学科名单。

Shopee是东南亚领航电商平台,覆盖新加坡、马来西亚、菲律宾、泰国、越南、巴西等十余个市场,同时在中国深圳、上海和香港设立跨境业务办公室。2023年Shopee总订单量达82亿,2024年第二季度总订单量同比增长40%,增势强劲。






