分享作者:王北南 Alluxio 技术负责人
Iceberg概览

Iceberg是一种开放式的table format,它主要是作为对标 Hive的一种文件,是一种表格存储的格式,主要的应对场景是比较大型的数据分析场景。它提供几种不同的功能,主要有 Schema evolution,hidden partitioning,partition layout evolution 和time travel,还提供version rollback的功能,很多功能是专门为了满足美国关于数据隐私法案的需求,提供事务性的支持。相对于Hive很难实现事务性的支持,Apache Iceberg提供了更好的支持。

Iceberg的schema evolution都是基于元数据操作的,没有任何的数据操作,可以增加column,drop column,可以rename column,也可以更新 column struct field,map key,map value或者 list element,甚至可以reorder,change the order of column or field in a nested struct。其实他们现在也支持z-ordering这种格式,为了让数据能得到更好的加速效果。
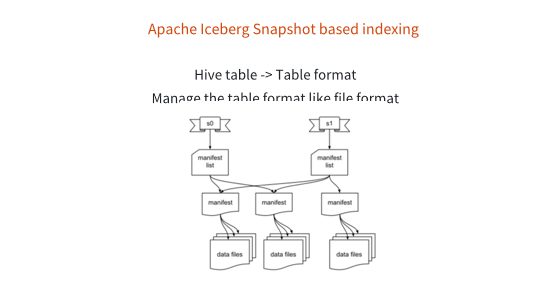
那么它是怎么实现事务性支持呢?它用了比较传统的数据库的理念,就是snapshot,它的不同的表格版本,是用snapshot来保护的,snapshot下面有一系列的manifest file来表征这个表在某一个特殊的时间点,比如说在11月27号,它是一个 snapshot,有可能过比如说一个小时或者是一天,它就更新一个snapshot,所以每个表格是通过snapshot去保证它的不同的版本的数据的一致性。
接下来我们来看一下为什么 Iceberg提出了这种方案。
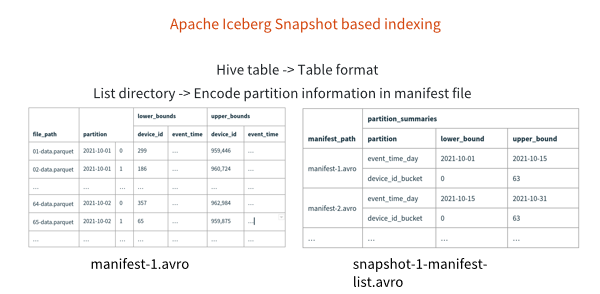
在大数据数据库的领域,大家原来都是用 Hive table,但是大家发现Hive table有很多问题,它就变成了一个table format。主要问题有我认为有两种,第一个是Hive table不支持事务性的,所以要支持 ACID非常困难。第二个是Hive table 是directory-based mechanism,所以每次去获取这个表格的全貌,都要通过底层的存储系统去list directory。在表格小的情况下,这不是一个非常重的开销,但如果是一个非常大的表格,比如说有上万个或者是上百万个partition的表格,开销会非常的昂贵,所以他们就提出一个概念叫encoding partitioning Information in manifest file,等于说它不需要通过 directory-based的概念去做这个事情了,而是把所有的数据都include到 table format里面去,直接去解析这个文件,来获取所有的文件位置。
然后我们可以看一下,比如说在右边manifest list里面,它会标注 manifest file在哪里,比如说manifest-1.avro这个file,它有一个partition的概念,event time是2021年10月11号到2021年10月15号,有一个最小的event date和最大的event date,然后对应到左边就可以找到 manifest file,这个 manifest file会对应所有的 Parquet文件,因为我们知道Parquet文件是通过最小值和最大值去做 predicate pushdown,等于说在这个概念里面,它就把所有的最小值和最大值都include到Iceberg的metadata里面去了,就不需要去list directory,去fetch parquet header获取做 predicate pushdown的元数据,而是可以一次性把所有的数据都拉过来,进行indexing的操作。大家如果对Iceberg的indexing比较感兴趣的话,我推荐大家去看下面的 tabular log,这是Ryan最新写的关于Iceberg如何做indexing的非常详细的blog,大家如果感兴趣可以看一下。
Alluxio+Iceberg 集成方案
我们发现Alluxio提供的是数据层面的东西,而 Iceberg提供的是表格层面的东西,它们两个关系非常远,但是为什么我们要把Alluxio的方案和 Iceberg的方案进行集成,我想来回答一下大家的问题。

首先我们发现,现在构筑一个大数据方案,是希望得到一个完整的方案,而不是只用一个Iceberg或Alluxio就可以完成一个数据湖的搭建,事实上自上而下需要很多不同的组件去组成一个数据湖的方案。比如说,如果是基于Iceberg,很有可能上面需要有元数据的管理层,下面是Iceberg这样的元数据format底层,再下面有可能是利用Presto或者Spark等不同技术搭建了 ETL或者OLAP的计算引擎层,然后再下面有可能是Alluxio这样的缓存层,最下面有可能是你自己的一些云计算存储或者HDFS存储。所以我们看到很多用户非常关心整个业务逻辑的搭建,认为Alluxio方案需要跟Iceberg进行集成。
那么现阶段Alluxio给Iceberg提供了哪些优势?
1.不管Iceberg放在私有云、公有云还是多云环境下面,Alluxio都可以给整个数据通道进行加速,给业务逻辑提供更好的数据本地性。
2.因为Iceberg相比Hive, 没有自己的服务去管理这些 file format,如果你要进行数据迁移,会比较麻烦,特别是比如说现在 Iceberg支持最好的是Hadoop,也就是基于HDFS那套接口,如果你要把这个方案迁移到比如说S3或者Azure上面,就会有一些问题,在这种场景下,如果用Alluxio,你只要用一套方案就可以解决所有的问题,不需要将不同的存储方案一个个地跟Iceberg进行适配,这其实在很多场景下是一件非常麻烦的事情。
3.很多公司的底层存储并不保证read-after-write strong consistent,那么你想要实现Iceberg的方案就非常困难,但是Alluxio可以避免这一点,你可以把这个文件写到Alluxio里面,Alluxio可以保证strong consistent的操作,你可以用Alluxio直接基于现在已有的 eventual consistent的系统来搭建数据湖。
我们下面来说一下,在已有的场景下,怎么将Iceberg的方案和Alluxio的方案进行集成。

为什么说集成需要比较小心,其实作为一个缓存层,我们不是在所有场景下完全的支持强一致性的,因为我们的写入有很多种方式,第一种是MUST_CACHE,在这种方式下,我们会把数据直接写入Alluxio,不写入底层的 HDFS集群或者S3集群。第二种方式叫THROUGH,一般不太关心写入的数据,后面要再被重复应用,所以不想把这个数据写回缓存层,直接写回底层的分布式存储。第三种是CACHE_THROUGH,就是同时写入Alluxio系统和底层的 S3或者HDFS。第四种方式是Eventual consistent的模式,写回Alluxio是strong consistent,但最后写回底层的存储,是一个Eventual consistent的模式。很多人会采用这种模式,因为比如说 object store s3的rename特别的昂贵,这种情况下,我们推荐通过ASYNC_THROUGH的方式写入,但有时候这个方式,对不同的基于Iceberg的数据湖方案就会有一些不同的影响。
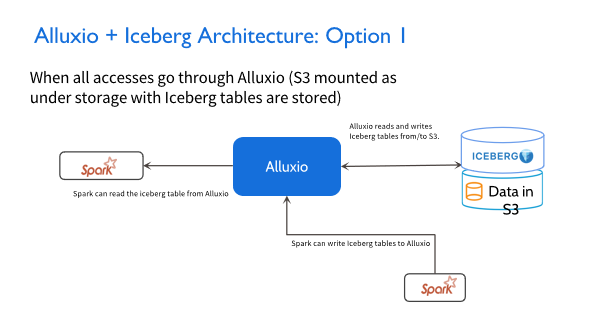
架构推荐
第一种架构比较简单,我们拿 Spark和AWS举个例子,左边 Spark是在私有云的场景,右边Spark是在公有云的场景,在这两个场景里都同时会写入Alluxio集群。所以在这种场景下,读写这两条线都没有太大的问题。因为这一端的强一致性是在Alluxio这层保护的,所以数据对Iceberg的事务性支持就可以得到非常好的控制。
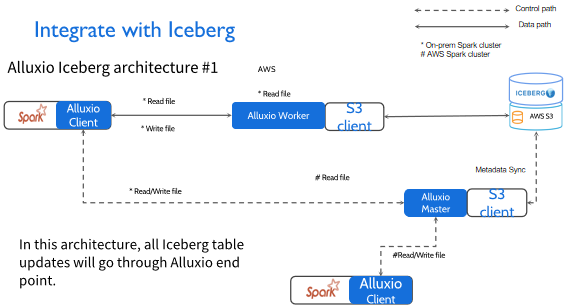
第二个场景比较复杂,也是很多用户常用的一种模式。比如在私有云场景里,我是写回Alluxio里面的,但在公有云里面我不希望通过Alluxio写回,因为我已经在AWS里面Run EMR job,所以我希望直接写回S3就可以得到一个比较好的性能。
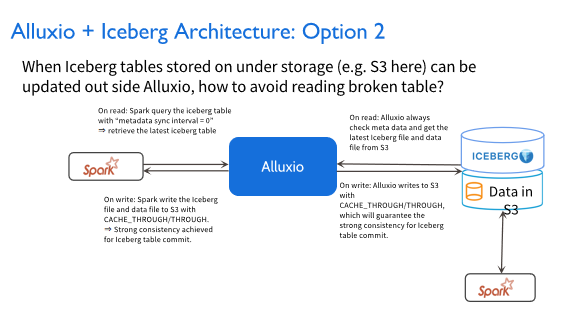
在这种场景下,当你写入数据的时候,我们推荐的是用THROUGH和CACHE_THROUGH的模式写回去,这样就保证私有云这一端写回S3时可以保持强一致性。
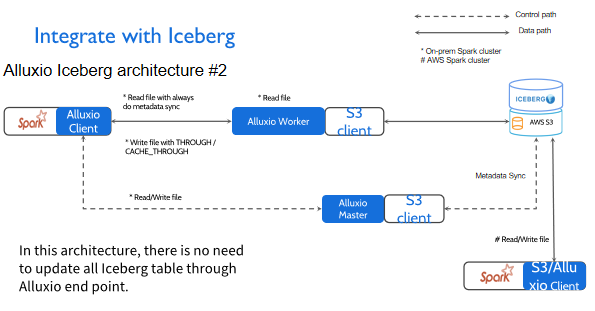
就算Spark job在AWS上面运行时拉取Iceberg的表格,它也可以拉取到最新的表格,而不是说通过ASYNC_THROUGH的方式,有可能你写进去过了几分钟或者是几十秒,你才发现这个表格更新了,此时你没有办法去update Iceberg的表格,也就没有办法保证数据的一致性。像AWS这种系统,它不提供 push机制告知更新,所以这种场景下我们一般会有一个周期性的检查,检查AWS是否更新,在这种场景下,我们推荐你在读Iceberg文件之前,总是进行元数据的同步操作,保证你每次拉取的数据都是最新的数据。
查询Iceberg表
Create Table
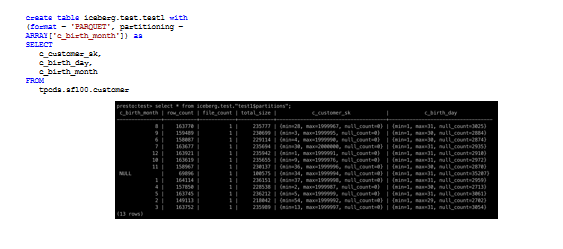
可能很多人用Presto只用 Hive Connector,其实Iceberg connector跟Hive差不多,不管从实现,还是从功能上都有互相的参照,尤其是在实现方面使用了非常多的Hive connector底层的代码。它创建table也是一样,我们可以从一个 TPC-DS数据的 customer表里抽几列再创建一个table,你可以指定这个数据的格式,可以是Parquet也可以是ORC格式。也可以同时指定分区(partition),这里用出生的月份这样会容易些,因为月份只有12个,也就是12个分区。我们创建了这个表之后,跟Hive表一样,你可以select这个表,select* from Iceberg.test,test1是表名,你可以用一个美元符号$加上partitions,这样你可以把这个表的所有分区给列出来。每个分区都会有一个统计,比如说下面第一行8月,能看到它有多少行有多少个文件,大小总共有多大,同时对于customer_sk这一列,能看到最小值多少最大值多少。后面的birth date就是日期,对于8月最小值是1,最大值是31,空值有若干。因为8月是大月,后面的9月是小月最大值是30,每一个partition都会有自己的统计,后面我们会再讲, predicate pushdown会用到这个,可以让我们跳过很多的分区,其实Hive也有这个功能,只不过可能有些数据在Hive metastore上,元数据这里没有的话,用不上这个功能,但在Iceberg上它内嵌在table里了,就会比较好用一些。
Insert

前面提到Iceberg会有一些事务(transaction)支持。我们试着往这个表里加入一行, SK是1000,日期是40,我特意插入了一个不可能存在的日期月份是13,这样等于说我新创建了一个partition。其实不管是不是新建partition都会产生一个新的快照(snapshot),在Presto里,通过select * from 表, 表的名字上面加一个美元$符号,然后再加一个snapshots,就可以列出这个 table所有的snapshots。大家可以看到有两个snapshots,因为新建table时出一个,插入一行之后又出一个,manifest list就有两个avro文件,第二个snapshot基于第一个,第二个snapshot 的parent ID就是第一个snapshot的parent ID,待会我们会用snapshot ID来做time travel。
对于这样一个文件,我们加了一个partition进去之后会怎么样,看一下这个目录,其实Iceberg的目录非常简单,我们指定一个目录,它在这下面就创建一个test1,里边有两个文件夹,一个是data (数据),一个是metadata(元数据)。数据里边是按照月份来分区的,这里面是 14个分区,因为12个月份,还有个空值,再加上我们新加的月份13,等于现在一共14个分区,这个文件就是这么组织的,而每个目录下面就是parquet文件。
Query
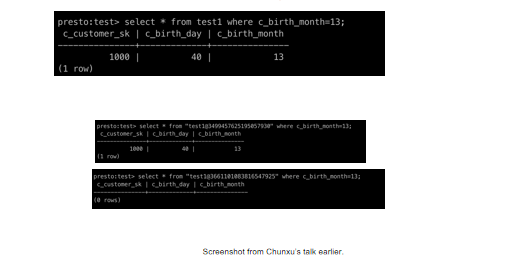
那么我们在query的时候会发生什么呢?
这个其实大家都会——写个SQL,从这个select*from Test1的时候,指定一个条件,我这个月份是13,那就把我刚才新插入的那一条记录给调出来了。我后面会介绍一下怎么做时间穿梭(Time travel),我们可以看到在这个表名test1这有个@符,后面我可以加一个 snapshot ID,如果我用第二个(快照)snapshot,就能查到这个记录,如果我用第一个snapshot就没有这个记录,为什么?因为第一个query发生在插入这条记录之前。这还挺有用的,因为有的时候就想查一下我这个表昨天是什么样的。但这也有问题,如果你频繁插入数据的话,就会产生大量的snapshot,avro里面就会有大量的数据。那我们是不是要丢掉一些过期的快照?这也是个优化点,现在presto还没有,但以后我觉得我们会把它做进去。
另外有些朋友会问,既然Iceberg connector有这个功能了,能不能用它来取代MySQL,做OLTP来处理一些在线的transaction数据? ——可以,但是不能像MySQL那么用,频繁的插入数据还会带来一些问题,需要做更深入的优化,直接这么用的话会产生大量的小文件和快照,但这些都有办法解决,我们后面会把它慢慢迭代进去。
Schema Evolution
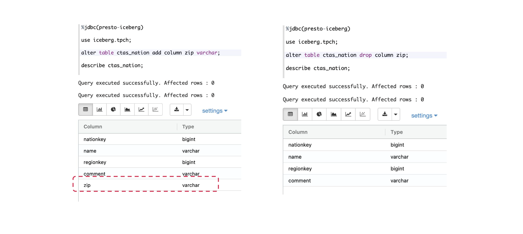
这个是我的前同事Chunxu做 Schema Evolution的时候截的一张图。可以看到这也是Iceberg的一个亮点,就是说这个表原来有几列,我可以加一列或者改一列,当然这也不难,因为原来 Hive table也可以这样做,但是做完之后,你的table还能不能查?Iceberg给我们的答案是 table改完了还能查,当然这里边也有tricky的地方,里面的数据也不是这么完整,但是不管怎么样它没出错,你先改好table,用老的query还能够查到。这个功能我觉得还是挺实用的,因为各个公司 table总在改,改完之后 table在presto这边还是可以查的。
Iceberg连接器更新
接下来会讲一下我们社区最近这一两个月的一些贡献,希望能够对大家有帮助,我主要讲是Presto DB,Trino那边是另外一套故事,尽量兼顾来讲。
New Features

最近这两三个月,有几个功能进来之后给我们的一些东西解锁了。
1.第一份credit要重点给亚马逊公司AWS 的Jack Ye,他做了一个 native folder的支持,这个在Iceberg叫做Hadoop catalog,盘活了我们的很多功能,解决了我们非常多的痛点。
2.另外就是腾讯的Baolong,他把local cache这个功能给加上去了,现在Iceberg connector可以和 RaptorX那一套,就是Hive connector里的cache,同样享受local cache,得到提速。当然这个不是那么简单,那么开箱即用,可能会需要一些配置,后面我会再详细地讲。
3.接下来就是Uber的Xinli Shang,我们俩给parquet做了升级。Xinli Shang是Parquet社区的chair,他给parquet做了升级后,我们拿过来放在presto里,我们的升级工作历时大概半年,升级到新的parquet之后,我们也解锁了Iceberg 1.12,有更多新的功能,包括对v2 的Iceberg table的支持。
4.还有一个predicate pushdown,在后面Beinan(Alluxio)也会详细地讲一下,这是可以优化查询的一个功能。
Iceberg Native Catalog
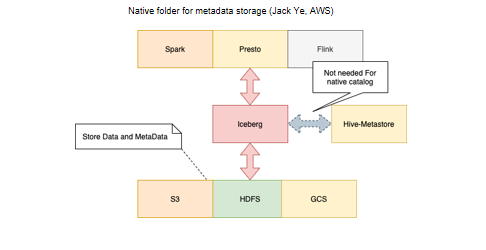
这就是我刚才提到的 Jack做的 native catalog——原来在Iceberg叫Hadoop catalog,其实Iceberg数据也是存在 S3、HDFS、GCS里的。它的每一个table下面既有元数据,又有数据,那为什么还需要Hive metastore,还要去Hive metastore里取元数据呢?这是因为最开始的Hive catalog还是要依赖Hive的元数据的,我们需要找到 table的路径,到这个table里把Iceberg自己的元数据加载出来,然后用 presto进行查询。有了 Jack这个很好的修改,我们可以支持Hadoop catalog,你直接给它一个路径,table都放在这个路径下面,它到这个路径上去扫一下,就可以录入所有的table,像table1,table2,table3, 每个table多少元数据,我们就不再需要Hive metastore了。有了这个native catalog之后, presto和Iceberg的结合就完整了。本来我们还依赖于一个额外的元数据存储,现在我们可以直接使用native catalog,这解决了非常多的痛点。
Iceberg Loca Cache
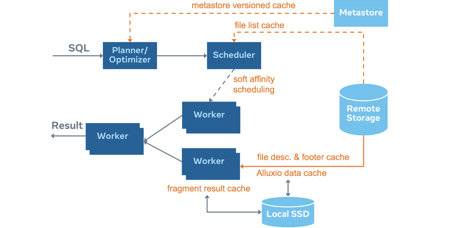
这个是之前有朋友问的 local cache,这个功能可能两个礼拜以前才merge的,腾讯的Baolong特别厉害几天就把这功能给做好了。那么为什么这个东西这么快就做好了,这个得从Iceberg connector的实现说起,是因为Iceberg connector和 Hive connector用的是一套东西,都是同一个Parquet reader或者是ORC reader。所以说我们当时在 RaptorX这个项目里,就是在 Hive下面做local cache,这个项目里用的很好的 local cache,在 Facebook、头条、还有Uber都取得很好效果,我们就把这个local cache直接搬到Iceberg里来用,直接能取得一个很好的效果。
这个里边有关键点得跟大家说一下,这个 local cache像是每个worker自己的私有缓存,它不像Alluxio cache那样,是一个分布式的、弹性的,可以部署比如说100个节点或200个节点,可以水平扩展的。但是这里不一样,这里边给你一个就近的小容量的local缓存,给每个worker可能500g或者1TB的一个本地磁盘,用来当作缓存使用。
这里就有一个问题, Presto在做plan的时候是随机分的,比如说每一个大的table下面有1万个partition,上面可能有100万个文件,随便拿一个文件,它不一定去哪个worker,每个worker cache不了那么多数据。于是我们就有一个soft affinity scheduling,有点像做负载均衡的时候会有一个affinity的功能一样,也就是粘连,比如说这个文件去work1,以后就一直去work1,这样的话work1只要把它cache了,你再访问这个文件它的cache命中率就提高了,所以这个affinity的功能是一定要打开的。
如果你发现local cache命中率很低,你就要看是不是affinity做的不对,是不是你的节点频繁增加或者减少,即使你什么都不调,你只要把 soft affinity打开,用一个比如说500g或者1TB的 local cache,它的命中率应该是不会低的,应该是有百分之六七十的命中率,这个是数据量很大的情况,数据量小的话可能有100%的命中率。
事实上就是Presto交给Iceberg来做一个plan。在收到SQL请求后,Presto解析,把 SQL拆一拆,告诉Iceberg要查什么,Iceberg就会生成一个plan,说要扫哪些文件,然后presto通过 soft affinity把这些文件分发给特定的worker,这些worker就会去扫这些文件,如果命中了本地cache扫本地文件,如果没命中本地cache就扫远程文件。其实Alluxio就是一个二级的存储,本地没命中去Alluxio,Alluxio还没命中去三级存储。
当然我们后续会有semantic cache,这个主要是给Hive做的,但是就像我前面提的,因为Iceberg和Hive底层的实现是同源的,因此结果我们都可以用。这里跟大家通报一个最新的进展,是AWS的Iceberg 团队Jack刚跟我们讲的,我们可能会不再使用presto的Hive 实现,当然这是可选的,你可以继续使用presto的 Hive实现,也可以使用Iceberg的native实现。这样以后Iceberg有什么新的功能,我们就不依赖Hive,这也是好事,而且我们可以引入更多向量化的东西,这是个长期的 plan,可能明年大家才会见到。
Iceberg Native Catalog
对于一个presto的查询来说,我们就说select* from table,比如说 city=‘Beijing’,profile age>18岁,这样一个查询,它其实就生成了左边这三个块的plan,先scan,scan完了给filter,filter完了给输出,其实就是扫完表之后,看哪些符合条件就输出但这个没有必要。比如说我们这个表是按照城市做的分区,没有必要扫整个表,而且每一个文件都有统计的,可能这个文件里年龄都是小于18岁的,就不用扫可以直接跳过了。
在 presto里有个connector optimizer,这个是prestoDB特有的一个东西,可以针对不同的connector来做优化,为什么要针对不同的connector做优化?因为很多人可能是一个Iceberg table去照映一个Hive table,这两个table底下 scan数据源是不一样的,所以你要决定到底把什么条件下推下去。其实有一个最简单的规则,就是Iceberg目前不支持profile.age这种有嵌套的字段的下推,那我就把 city下推,就把city的 filter下推到table scan,和table scan合并成一个plan节点,就是这个地方既做filter又做scan,然后下推给Iceberg,这里我把age>18岁留着,scan好了之后再filter,这个不是最优的方案,但这是最基本的规则。
Predicate Pushdown Resource Usage

我们来看看效果,这不是一个正规的Benchmark,就是刚才我建的 table,新加了一条记录,月份等于13的那个,如果我不开下推的话,是左边这种情况,它扫了200万条记录,input数据是200多KB;开了下推之后,它只扫描一条记录,时间和数据都有非常大的提升,它只扫特定的分区。这种查询在现实中遇不到,因为现实中肯定是有更多的组合,每个partition下面可能还有更多的文件,这里比较极端一些,只有这一个文件。其实这样效果不明显,文件越多效果越好,推荐大家试一试。
之前提到了 Native Iceberg IO,我们会使用Iceberg reader和writer来取代Hive实现,让它彻底的分开,也可能两个都支持,这个就是我们将要进行的工作,敬请期待。
Ongoing Work

另外一个是物化视图(materialized view),是我的前同事Chunxu在做的,这也是重要的一个功能,让临时表能够把数据存到一起,这个也没有那么简单, Facebook也有同事在做这个。我们这里不再多说了,Facebook很快会有一个关于物化视图的新的博客出来。
我会继续把v2 table实现一下删原来只能是按照分区来删,不能删除某一行或某几行,因为删除操作和insert是一样的,会再产生一些新的文件,标注说你这几行要被删掉了,然后真正出结果的时候,会把它合并到一起。现在是不支持这个功能的,那么我们要想支持这个功能,有两个做法,一个是使用 native Iceberg IO,另外一个就是在 Parquet的 reader上把要删的这些行标注出来,表示这些行不再显示。









