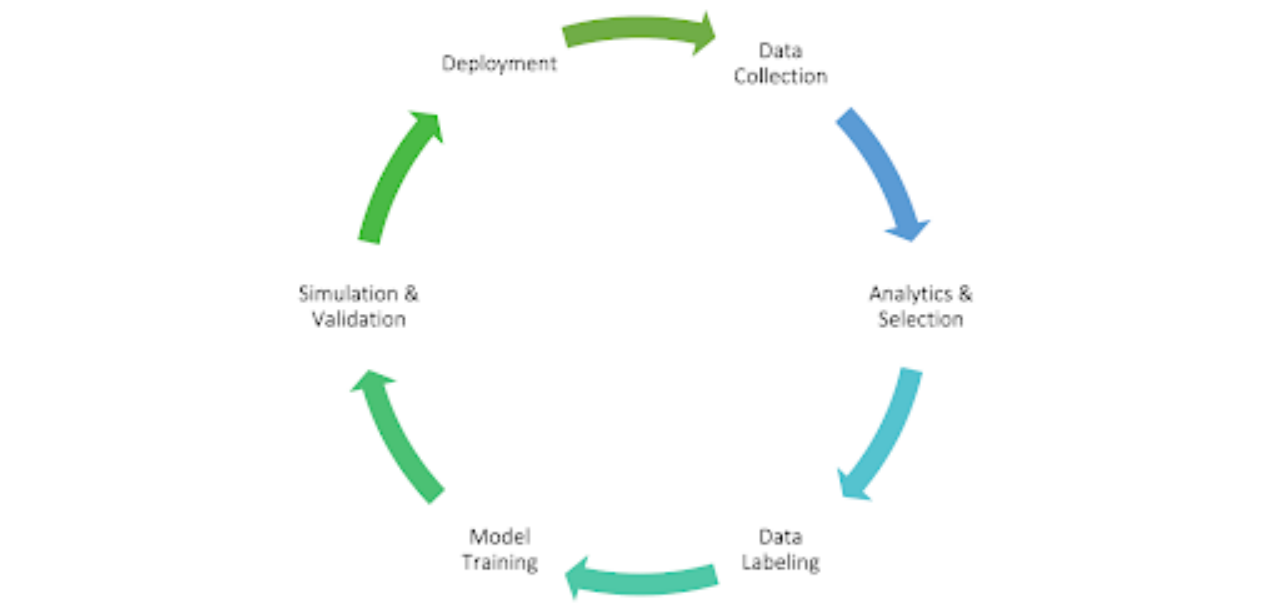
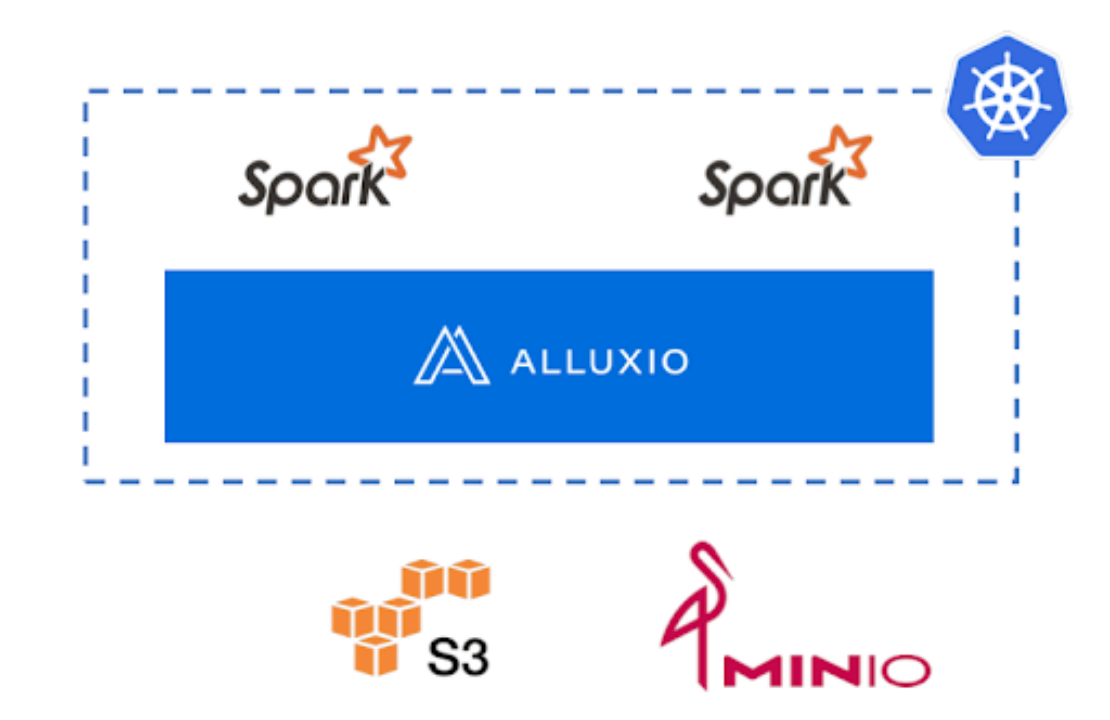
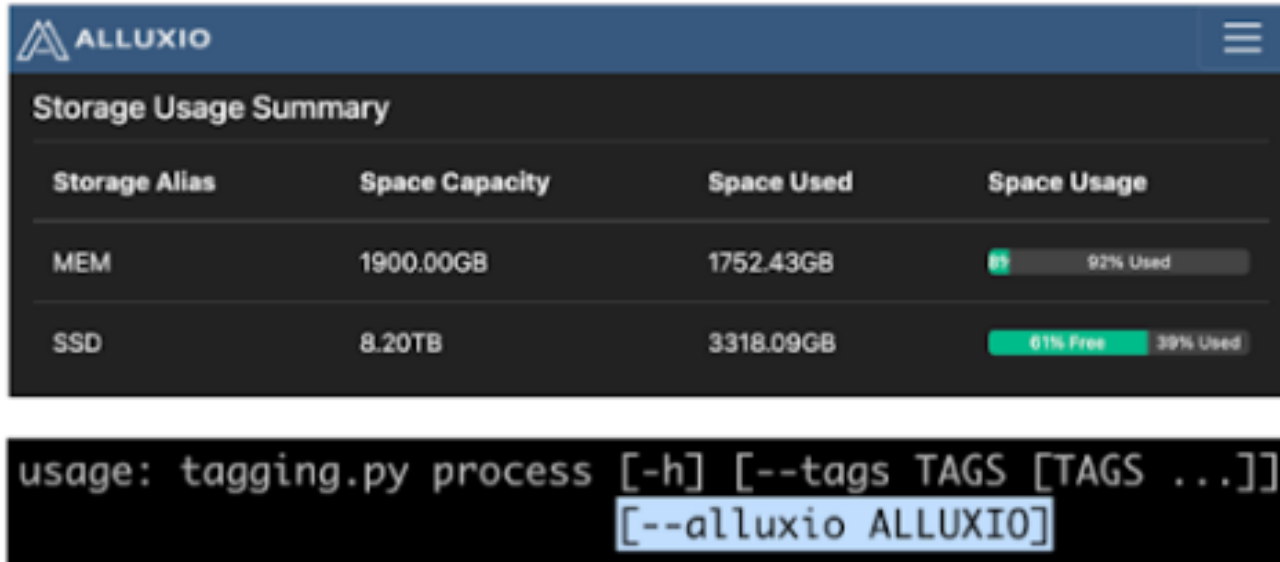
从上面可以看出,该系统架构相当典型。我们在公有云和本地数据中心的混合云上构建和运行应用程序,出于以下考虑:本地数据中心更具成本效益且可定制,而公有云易于扩展。在公有云和本地数据中心中,我们都使用 Kubernetes 来管理 CPU 和 GPU 集群的计算资源,并调度工作流程和任务。在存储层,我们使用MinIO构建S3兼容的对象存储服务。Alluxio 提供了一个快速、简化、统一的数据层,可以桥接 S3、MinIO 和 Spark 以及其他数据分析应用程序,从而通过 Alluxio 的引入加速数据标记工作流程。