关于辉羲智能
辉羲智能致力打造创新车载智能计算平台,提供高阶智能驾驶芯片、易用开放工具链及全栈自动驾驶解决方案,助力车企实现优质高效的自动驾驶量产交付,构建低成本、大规模和自动化迭代能力,引领数据驱动时代的高阶智慧出行。作为新型基础设施建设者,辉羲智能创导“数据闭环定义芯片”方法学,依托高性能低功耗的自动驾驶芯片底座,与客户和合作伙伴共建硅上超级数据闭环,持续助推行业标准、赋能产业生态,让更多创新企业和广大消费者受益。目前公司已获多家知名机构投资,并在北京、上海、合肥、杭州、宜宾多地设有研发中心。

遇到的挑战
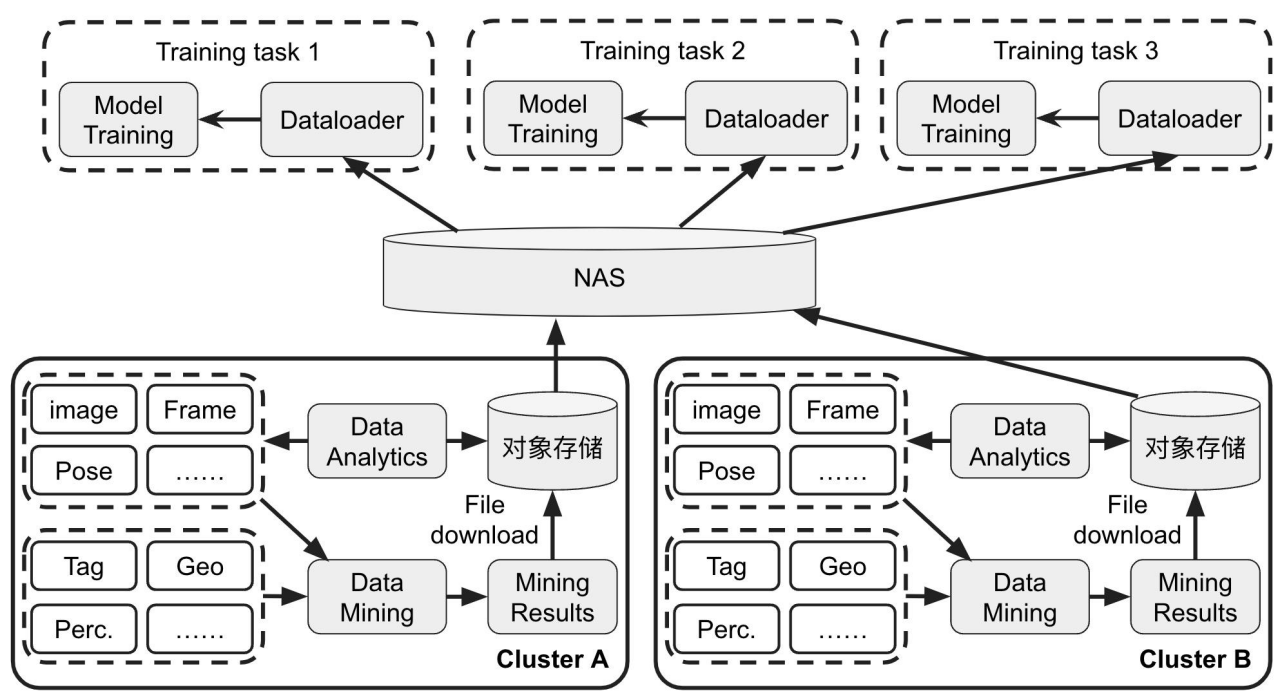
辉羲智能在使用Alluxio之前,有两个GPU集群,分别是视拓云和商汤云,同时,采购了NAS作为缓存在使用。但是在使用的过程中遇到了以下挑战和困难:
-
NAS作为缓存在使用,但算法用户会经常以高并发的方式从NAS读写数据,导致NAS性能很差;
-
很多相同的数据集被不同的用户重复拉取到NAS中,造成了大量的数据冗余存储,且没有去重的能力;
-
GPU资源的利用率不高,仅有30%到50%。
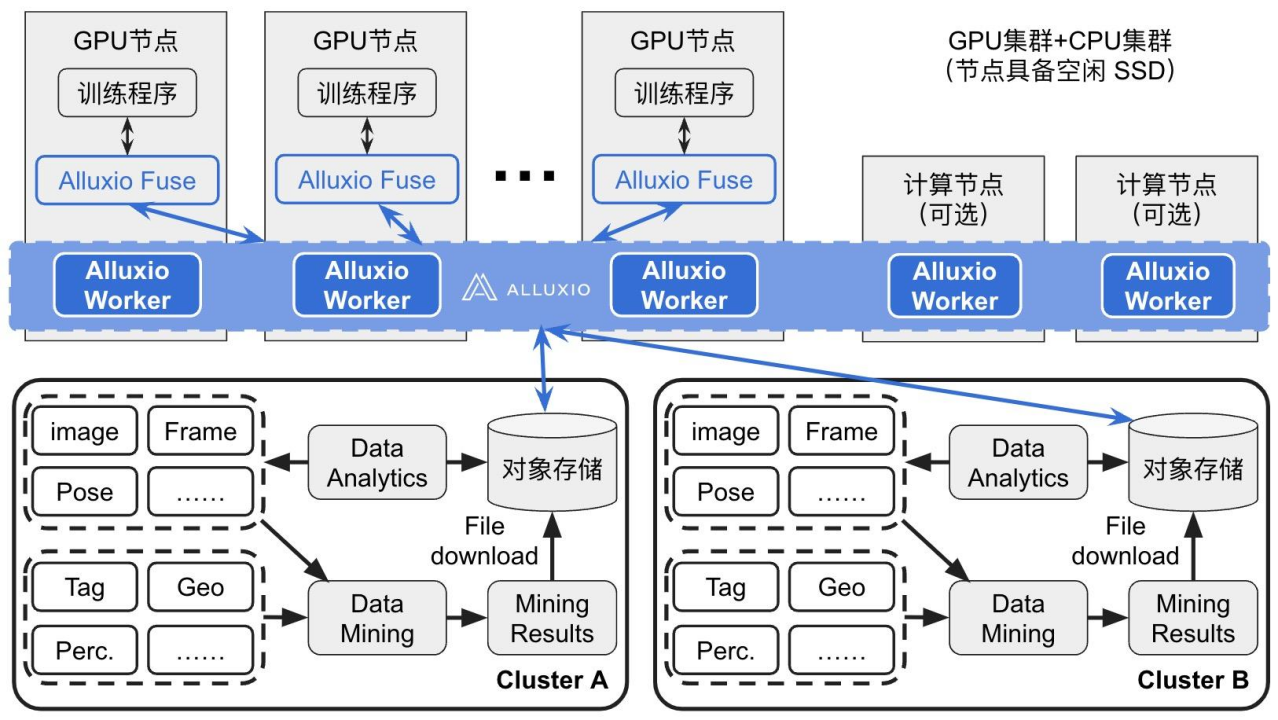
Alluxio的解决方案和价值
辉羲智能经过慎重的考虑,采用了Alluxio的解决方案。如下图所示:
在PoC的过程中,主要有以下方面的性能提升:
- 吞吐量提升明显:Alluxio通过bucket进行读写操作时,相比于NAS和直接访问S3存储桶,展现出显著的吞吐量提升。在FIO测试中,Alluxio的读取速度接近8GB/s,而NAS仅为1.45GB/s;
- S3数据下载更快:在进行大量数据传输时,Alluxio同样展现出更快的速度。例如,在S3数据下载测试中,Alluxio通过bucket完成了158GB数据的传输,平均速度为61.9MB/s,而NAS的平均速度仅为27.7MB/s。在Alluxio单bucket精细化调优的版本下,平均速度可到达277.2MB/s;
- 训练耗时更短:在预估完成时间的对比中,Alluxio的表现也更为出色。例如,Alluxio只用了约14小时51分钟,而NAS则需要17小时59分钟,因此能缩短30%的训练时间。
总体来说,Alluxio对于辉羲智能主要带来了以下价值:
- Alluxio作为分布式缓存系统,当数据规模及GPU侧并发访问较大的场景下,Alluxio会比NAS系统具有更好的性能;
- Alluxio能够利用GPU节点上的现有NVME资源来构建分布式缓存系统,从而加速模型训练,而无需增加新的NAS节点,减轻了潜在的成本压力;
- Alluxio能够在首次模型训练时自动从对象存储中按需拉取训练数据,无需通过其他方式将数据从对象存储迁移到NAS系统。同时,它还能通过自动缓存淘汰策略灵活管理缓存文件和空间,降低了整体运维成本,无需手动维护或删除旧数据集;
- 统一命名空间:将seeta cluster 和SenseCore cluser数据进行统一的数据管理,并且形成统一的目录视图,降低跨集群、跨数据中心的数据访问技术实现成本。









