作者简介

邱璐:机器学习工程师 @alluxio,Alluxio PMC maintainer, 有多年开源贡献经验。Alluxio机器学习、深度学习、POSIX API 方向负责人。熟悉Alluxio 选举机制、日志、指标系统等核心组件。

范斌:Alluxio 公司的创始成员和 VP of Open Source。加入 Alluxio 前, 范斌在 Google 从事下一代大规模分布式存储系统的研究与开发. 范斌博士毕业于卡内基梅隆大学计算机系, 博士期间在分布式系统算法和系统实现等方向发表多篇包括 SIGCOMM, SOSP, NSDI 等顶级国际会议论文以及多篇专利。
在本文中,我们将介绍 Alluxio 的 AI/ML(人工智能/机器学习)模型训练解决方案。关于参考架构和基准测试结果的更多信息,请到文末下载并查看完整白皮书。
01 背景:AI/ML 模型训练对数据平台的特殊要求
随着人工智能(AI)和机器学习(ML)的广泛应用以及在业务上的重要性不断增强,企业也在大力发展 AI/ML 的应用,这些应用要求数据平台满足以下要求:
具备对海量小文件的频繁数据访问的 I/O 效率
AI/ML 工作流不仅包含模型训练和推理,还包括前期的数据加载和预处理步骤,前期数据处理对整个工作流都有很大影响。与传统的数据分析应用相比,AI/ML 工作负载在数据加载和预处理阶段往往对海量小文件有较频繁的 I/O 请求。因此,数据平台需要提供更高的 I/O 效率,从而更好地为工作流提速。
提高 GPU 利用率,降低成本并提高投资回报率
机器学习模型训练是计算密集型的,需要消耗大量的 GPU 资源,从而快速准确地处理数据。由于 GPU 价格昂贵,因此优化 GPU 的利用率十分重要。这种情况下,I/O 就成为了瓶颈——工作负载受制于 GPU 的数据供给速度,而不是GPU 执行训练计算的速度。数据平台需要达到高吞吐量和低延迟,让 GPU 集群完全饱和,从而降低成本。
支持各种存储系统的原生接口
随着数据量的不断增长,企业很难只使用单一存储系统。不同业务部门会使用各类存储,包括本地分布式存储系统(HDFS和Ceph)和云存储(AWS S3,Azure Blob Store,Google 云存储等)。为了实现高效的模型训练,必须能够访问存储于不同环境中的所有训练数据,用户数据访问的接口最好是原生的。
支持单云、混合云和多云部署
除了支持不同的存储系统外,数据平台还需要支持不同的部署模式。随着数据量的增长,云存储成为普遍选择,它可扩展性高,成本低且易于使用。企业希望不受限制地实现单云、混合云和多云部署,实现灵活和开放的模型训练。另外,计算与存储分离的趋势也越来越明显,这会造成远程访问存储系统,这种情况下数据需要通过网络传输,带来性能上的挑战。数据平台需要满足在跨异构环境访问数据时也能达到高性能的要求。
综上,AI/ML 工作负载要求能在各种类型的异构环境中以低成本快速访问大量数据。企业需要不断优化升级数据平台,确保模型训练的工作负载在能够有效地访问数据,保持高吞吐量和高 GPU 利用率 。
02 为什么使用 Alluxio 进行模型训练
Alluxio 是用于分析和机器学习应用的开源数据编排平台。Alluxio 不仅在训练作业和底层存储之间提供了一个分布式缓存层,而且还负责连接到底层存储,主动或按需获取数据,根据用户设置的策略缓存数据,并将数据提供给训练框架。
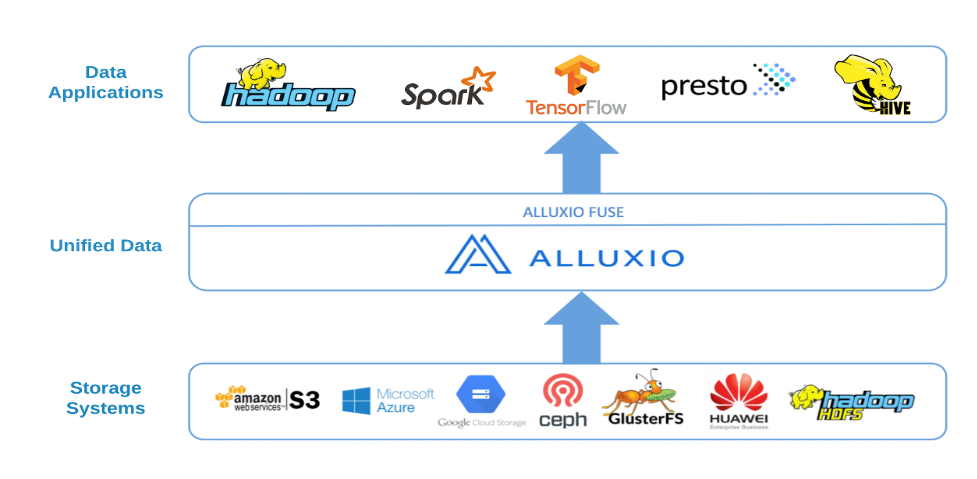
Alluxio 为满足 AI/ML 训练工作负载的特殊要求提供了有效的解决方案。Alluxio 数据编排平台统一了异构环境中的数据孤岛,并允许应用程序充分利用计算资源,突破数据访问的 I/O 瓶颈。
高性能、高 GPU 利用率的快速数据访问
Alluxio 对数十亿文件的 AI/ML 工作负载进行优化,降低延迟并缩短训练时间。Alluxio 通过预加载数据和在本地或靠近训练作业的节点缓存数据,消除 I/O 瓶颈,让模型训练工作流能够保持高性能和高数据吞吐量。在访问 Alluxio 中缓存的数据时,吞吐量保持在比较高的水平,无需等待数据缓存完毕才开始训练,从而大大提高模型训练的效率。
在高数据吞吐量的情况下,模型训练工作流各个步骤的数据都被缓存在本地计算实例上,GPU 无需等待网络 I/O ,因此始终处于忙碌状态。这样可以充分利用计算资源, 显著降低成本并提高性能。
跨单云、本地、混合云和多云环境的灵活数据访问
目前,将 AI/ML 存算分离越来越普遍,因为存储可以独立于计算进行扩展,降低了资本支出和运营费用。企业希望将数据存储在本地,同时利用公有云上灵活的计算资源,或在使用本地计算资源的同时访问云对象存储。但是,对于模型训练的工作负载而言,访问远程数据时,网络延迟会导致性能降低。
Alluxio 通过高级缓存和数据分层使存算分离不再成为一个挑战,AI /ML 工作负载在单云、本地、混合云和多云环境中访问数据时速度更快、成本更低。Alluxio 将多数据存储统一为类似本地存储的逻辑数据层,从而解决了数据访问问题。
对整个数据分析和模型训练工作流进行提速
Alluxio 既是高级的缓存解决方案,也是数据编排平台,它连接了训练/计算框架和底层存储系统。部署 Alluxio 不仅有助于训练,也有利于数据工作流其他阶段的作业,包括数据导入、数据预处理和训练。
Alluxio 数据编排平台支持从数据导入到ETL再到分析和 ML 的整个数据工作流。Alluxio 实现数据数据共享并存储中间结果,让一个计算引擎可以使用另一个计算引擎的输出。这种在应用之间共享数据的功能进一步提升了性能,减少了数据移动。Alluxio 的数据管理功能对端到端整个工作流(包括数据预处理、加载、训练和输出)都起到了很好的支持作用。
从本质上讲,Alluxio 消除了 AI/ML 训练工作流的数据加载和预处理阶段的I/O瓶颈,降低了端到端训练的时间和成本。基准测试表明,Alluxio 将 I/O 效率提高了 9 倍。关于详细的参考架构和基准测试方法,请到文末下载并查看完整白皮书。
03 使用 Alluxio 进行机器学习模型训练技术和解决方案概述
Alluxio 允许训练通过 FUSE API 连接到远程存储并提供缓存。此外,Alluxio 为任务或节点提供分布式缓存,共享缓存数据。分布式数据预加载、pin 数据等高级数据管理策略还可以进一步提高数据访问性能。
分布式缓存
Alluxio 不是将整个数据集复制到每台机器上,而是提供共享的分布式缓存服务,使得数据在集群中均匀分布。这可以大大提高存储利用率,当训练数据集远大于单个节点的存储容量时更是如此。
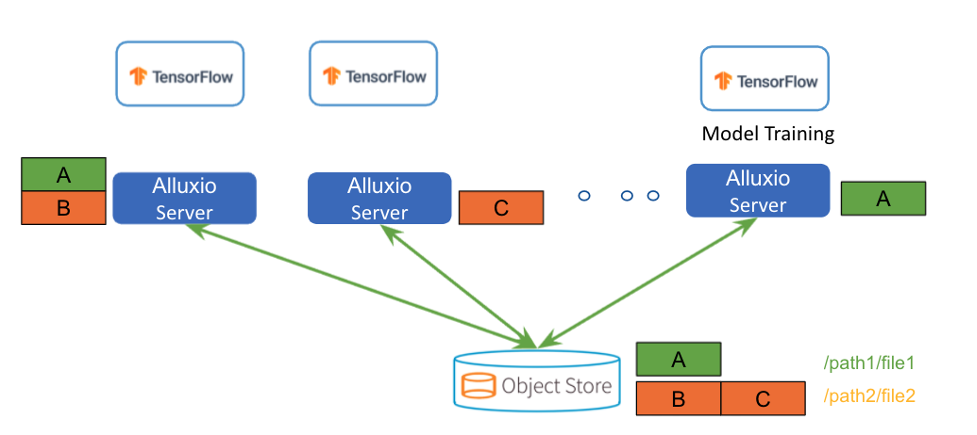
元数据操作
Alluxio 缓存云存储系统的元数据,并代替云存储系统来为训练供给元数据信息。如果数据在云存储中被修改,Alluxio 提供定期同步功能来确保 Alluxio 缓存的元数据能与数据源达到最终一致。
高级数据管理策略
Alluxio 提供一系列数据管理策略,可以有效管理存储资源,优化数据缓存。Alluxio 有不同的策略供用户使用,包括自动高效数据替换策略,pin 和 free 缓存中的工作集,设置缓存中数据的 TTL(生存时间),以及数据备份。通过使用以上数据策略,用户可以进一步管控 Alluxio 中的数据。
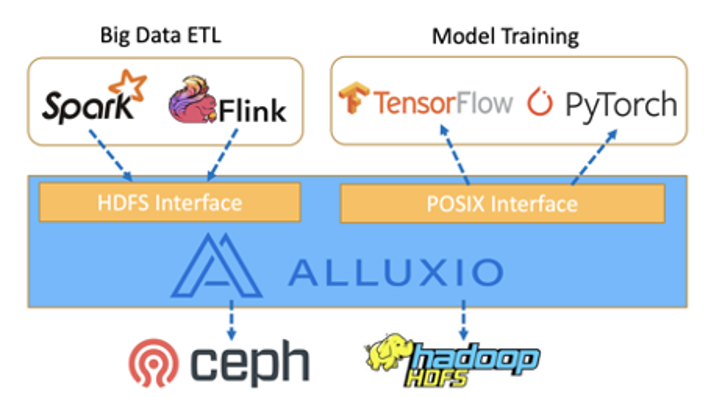
支持多种 API 和计算框架
Alluxio 支持多种 API,例如在大数据应用 (比如 Spark, Presto 等)中流行的 HDFS 接口。新的 POSIX 接口适用于 PyTorch、Tensorflow 和 Caffe 等训练应用。用户可以使用大数据框架对数据进行预处理,将其存储在 Alluxio中,并异步持久化到底层存储,同时使用训练框架和Alluxio 中预处理的数据来训练模型。
04 技术的演进和生产环境案例分析
Alluxio POSIX 接口是 2016 年 2 月在 Alluxio v1.0中首次添加的一个实验性功能,由来自 IBM 的研究人员贡献。一开始为了支持那些非 HDFS 接口的传统应用使用,因此在功能和性能方面发展缓慢。2020 年初,机器学习训练工作负载激增,推动了这一功能的发展并开始用于生产环境。不仅如此,Alluxio 核心团队一直在与开源社区,包括阿里巴巴、腾讯、微软的工程师和南京大学的研究人员密切合作,成功解决了数百个问题,取得了重大进展(例如,基于JNI的FUSE接口,容器存储接口,海量小文件的性能优化等)。
如今,全球最领先的数据密集型企业都在生产环境中部署了 Alluxio,通过将 Alluxio 集成到其机器学习平台中为工作流提供支持,实现了显著的性能提升。
Boss 直聘
Boss 直聘(NASDAQ: BZ)是中国最大的在线招聘平台。在 Boss 直聘,Alluxio 用作底层存储 Ceph 和 HDFS 的缓存存储。Spark 和 Flink 从 Alluxio 读取数据,对数据进行预处理,然后写回 Alluxio 缓存。Alluxio 在后端将预处理后的数据持久异步写回底层存储Ceph和HDFS。Tensorflow、PyTorch 和其他 Python 训练应用无需等待Ceph 或 HDFS 写入完成,就可以从 Alluxio 读取预处理数据来进行训练。请点击此处查看演讲视频回顾。
腾讯
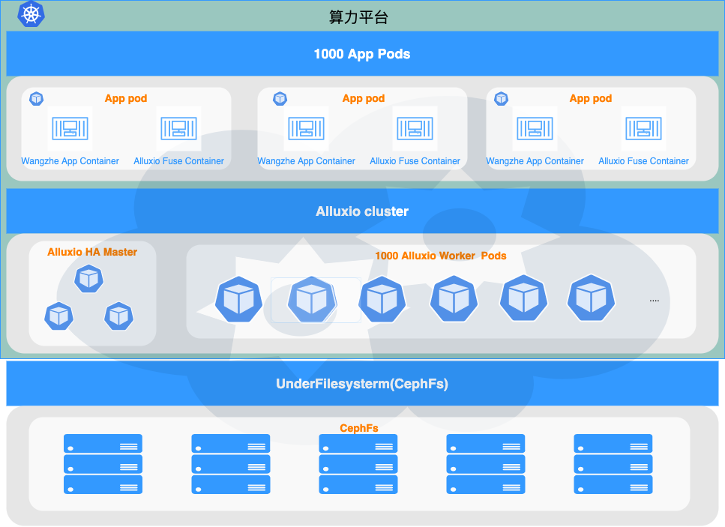
腾讯在包含 1000 个节点的集群中部署了 Alluxio,用来加速游戏AI平台上模型训练的数据预处理。Alluxio 有效提高了AI工作负载的并发度,同时降低了成本。由于使用 POSIX API 来访问 Alluxio,因此对应用程序没有影响。
微软必应
微软必应团队使用 Alluxio 来加速大规模机器学习/深度学习(ML/DL)离线推理。Alluxio成功加速推理作业,降低I/O 卡顿,并实现 18% 的性能提升。请点击此处查看演讲视频回顾。
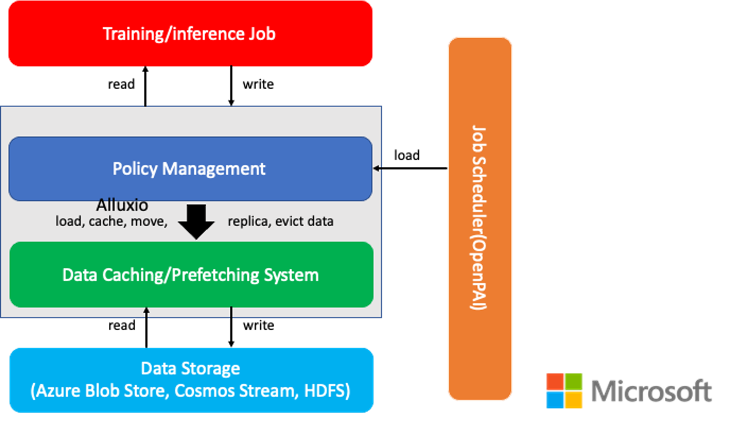
云知声
Unisound(云知声)是一家专注于物联网服务的 AI 公司。该公司在 GPU/CPU 异构计算和分布式文件系统中使用Alluxio,作为计算和存储之间的缓存层。由于 Alluxio 将底层存储带到每个计算节点的内存或本地硬盘中,用户可以快速地访问数据。平台可以同时利用分布式文件系统和本地硬盘中的资源。请点击此处查看详细内容。
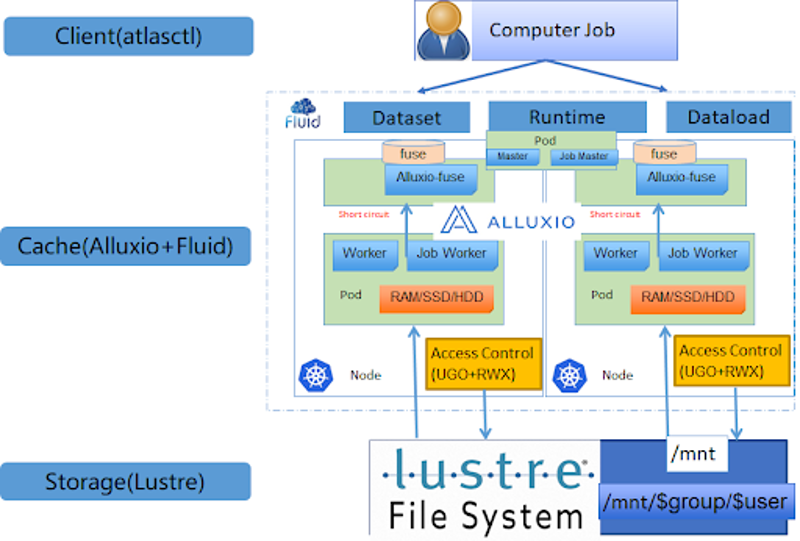
陌陌
Momo(陌陌)在生产中部署了多个 Alluxio 集群,包含数千个 Alluxio 节点。Alluxio 帮助陌陌实现计算/训练任务提速,并降低了数十亿图像训练在底层存储中的元数据和数据开销。请点击此处查看演讲视频回顾。
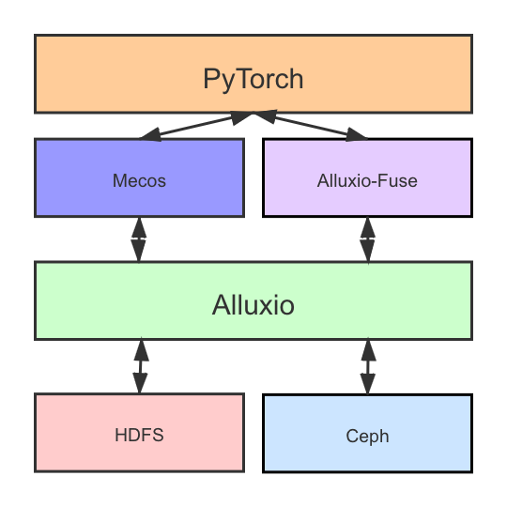
05 准备好部署了吗?
在本文中,我们介绍了 Alluxio 解决方案如何提升训练性能和简化数据管理。综上所述,Alluxio 提供了以下优势:
· 分布式缓存,允许任务和节点之间共享数据。
· 跨多个数据源的统一数据访问。
· 加速端到端工作流,包括数据导入、数据预处理和训练。
· 高级数据管理策略,包括数据预加载和 pin 数据,进一步简化数据管理, 实现性能提升。
关于架构和基准测试的详细信息,请下载完整白皮书《加速机器学习/深度学习:架构和性能测试》。如果要使用 Alluxio 进行模型训练,请查看此文档了解更多信息。访问官网下载免费的 Alluxio 社区版或 Alluxio 企业版的试用版,部署到您的 AI/ML 平台中。









