Presto(PrestoDB和Trino)是非常流行的多个数据源上运行大规模交互式分析查询的计算引擎。Presto的定位是SQL-on-Everything,作为不依赖于存储的查询引擎,可以用来查询在任何位置的分散数据源。
为了满足当下和未来的需求,很多公司不断升级数据平台并开发可扩展的解决方案。从现有的实践来看,虽然Presto具有处理海量数据的能力,但其在跨工作流的数据访问方面优化不足。因此,数据平台工程师还需要寻找其他的方案来解决数据冗余、易出错、性能缓慢、不稳定和高成本的问题。
为了解决这些挑战,我们提出了一个创新架构,建议搭配部署Presto和Alluxio。
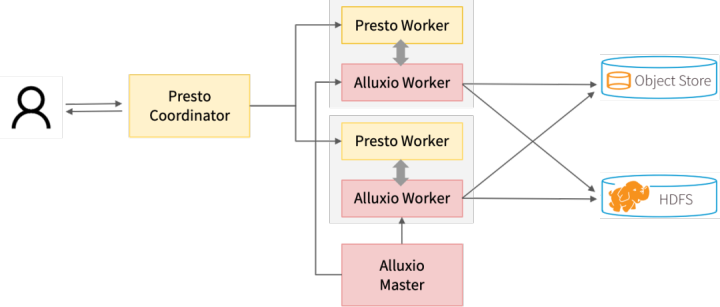
Alluxio是一个数据编排平台,连接计算框架和底层存储系统的。Presto和Alluxio的协同工作可实现统一、强大、高性能、低延迟和低成本的分析架构。该架构不仅有利于分析,而且有利于数据工作流各阶段的工作,包括数据导入、分析和建模。这个架构支持跨本地、公有云、混合云和多云环境中的多个存储系统进行快速 SQL 查询。
全球众多公司已经利用Alluxio来升级其当前的Presto平台,包括Facebook、TikTok、美国艺电(Electronic Arts)、沃尔玛、腾讯、康卡斯特(Comcast)等。他们把Alluxio 集成到Presto技术栈中,实现了很多益处。以下将介绍为何以及如何搭配使用Presto+Alluxio。
立即下载白皮书。了解更多精彩内容!










