美国艺电 (EA) 是游戏行业的翘楚,每年为全球几十亿用户提供数十款游戏。能否针对EA的在线服务做出近实时决策对于业务发展至关重要。本文介绍了在AWS上搭建的基于Presto和Alluxio的数据平台,如何为游戏产业提供即时响应的在线服务。

EA的数据与人工智能部门搭建了数百个平台,来管理游戏和用户每天产生的PB级数据。这些平台包含从实时数据导入到 ETL工作流在内的各类数据分析作业。部门产生的格式化数据已经被公司高管、制作人、产品经理、游戏工程师和设计师等广泛采纳,用于市场营销和货币化、游戏设计以及提升客户参与度、玩家留存率和终端用户体验。
用例
EA的在线服务需要能够获取近实时信息,这对于制定业务相关的决策(如推广活动和故障排查)至关重要。这些服务包括但不限于实时数据可视化、仪表板(dashboarding) 和会话分析,我们的团队正在积极寻找可以支持这些用例的框架。
在EA,为获取支持决策的数据分析结果,我们采用了诸如 Tableau 和 Dundas等一系列的数据可视化工具。这些工具通常连接多个数据源,例如 MySQL DB、AWS S3 或 HDFS。用户可能同时从多个数据源加载数据来运行计算复杂度较高的算法。由于数据加载是 I/O 密集型的,因此可能成为严重的性能瓶颈。尤其当相同的数据需要被多次加载时,性能瓶颈问题可能更严重。因此,我们需要一种解决方案,通过在本地缓存数据的方式来降低数据的访问开销。
仪表板是另一个常见的用例,用于实时追踪用户参与度、客户满意度或系统状态。在这些场景下,数据量通常是GB级的,但需要能够对频繁的信息刷新进行即时处理。目前,我们使用Redshift等商业数据库来处理时间敏感型数据,希望寻求一种在不降低性能的情况下削减成本的替代方案。
我们最近开发了一款汇报式聊天机器人,来提供即时的游戏相关分析,例如实时用户满意度和实时利润分析。该系统的后端运行 Presto,PB级的数据存储在 S3 上。聊天机器人会将用户的提问转换为 ANSI SQL查询语句,并在 Presto 集群上运行这些查询。查询通常会涉及复杂的计算过程,例如在跨数据集搜索后进行预测和合并。我们迫切希望找到一种解决方案,与基于S3存储的数据集互补,确保在不增加成本的情况下提高性能。
架构
为了服务这些具有近实时需求的不同用例,我们搭建并评估了以Presto为查询引擎,S3为数据存储,Alluxio为作业数据集缓存层的数据平台。文中,我们模拟了上述在当前生产环境中搭建的基于S3的 Presto(没有Alluxio)架构,与环境设置(Presto和S3)相同但部署了Alluxio的技术方案进行比较。架构如下图所示:
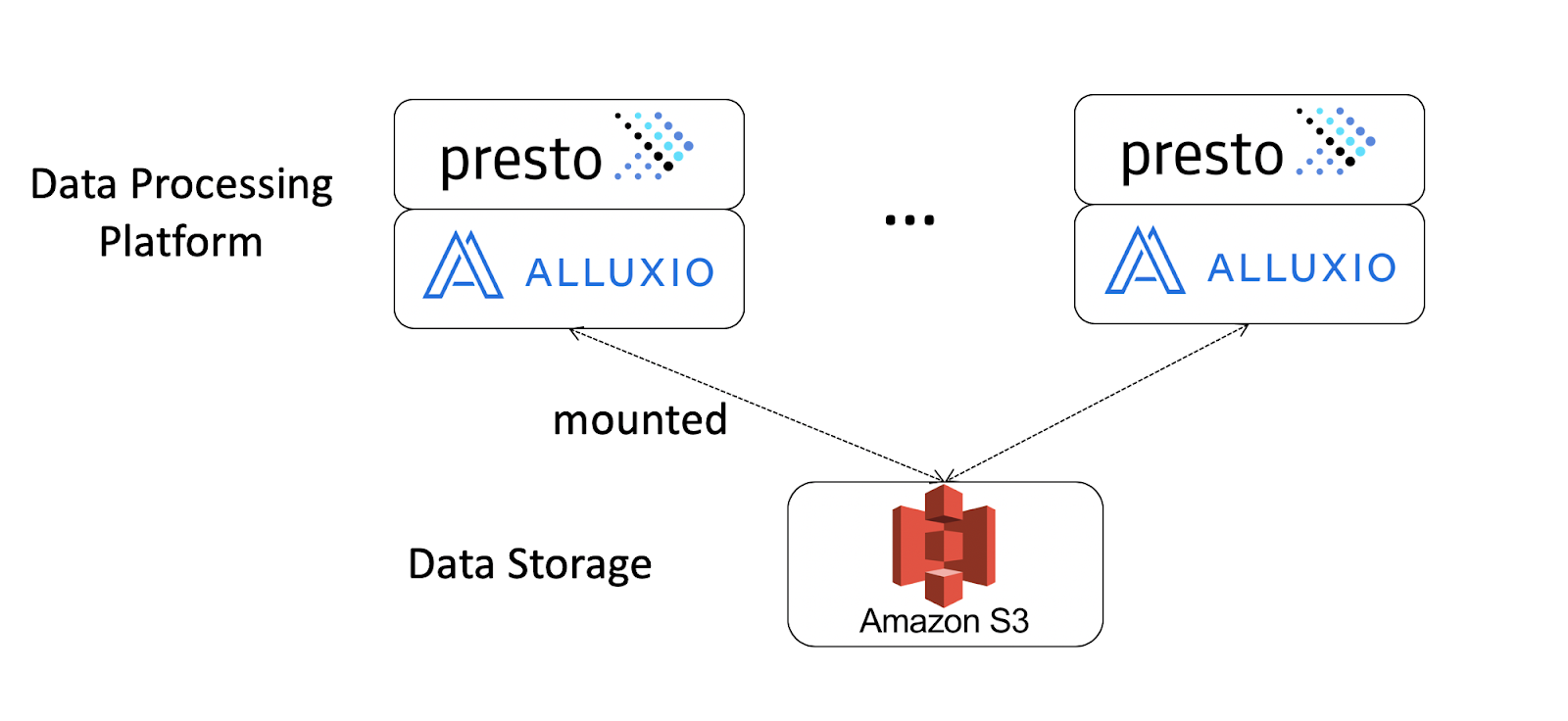
关于设置的具体信息如下:
- 每个实例启动并置的Presto 和Alluxio服务。
- 硬件方面,我们使用了三个 h1.8xlarge AWS 实例,每个实例上都挂载了 8TB 临时磁盘,供Alluxio把数据缓存到Presto 的本地位置。
- S3 作为底层持久文件系统挂载到Alluxio。
- Presto 配置了两个目录;一个连接到我们现有的 Hive metastore,关联到存储在外部S3 上的基准测试数据集,另一个连接到一个单独的Hive metastore,其中包含在 Alluxio 中创建的基准测试数据表。
- 我们在 S3 上使用相同的数据集进行性能比较,并通过 alluxio fs distributedLoad /testDB指令将数据预加载到 Alluxio。
- 为了提升处理海量小文件时的查询性能,我们在alluxio-site.properties 中启用了元数据缓存功能来进行性能调优。
alluxio.user.metadata.cache.enabled=true
alluxio.user.metadata.cache.max.size=100000
alluxio.user.metadata.cache.expiration.time=10min
基准测试结果
基准测试1
结果
基准测试2
结果
基准测试3
结果
基准测试4
结果
结论









